Why World Models?
왜 World Model인가 — LeCun의 비전
Yann LeCun이 2022년에 던진 질문: '지능이란 결국 미래를 예측하는 능력이다. 그럼 AI도 자기 안에 세상의 모형(World Model)을 가져야 하지 않을까?' 이 한 문장이 JEPA 시리즈의 출발점이다.
Overview
2022년 6월 27일, Meta의 수석 AI 과학자이자 Turing Award 수상자인 Yann LeCun(얀 르쿤)이 39페이지짜리 비전 문서를 OpenReview에 공개했다. 제목은 "A Path Towards Autonomous Machine Intelligence"(자율적 기계 지능으로 가는 길) v0.9.2. 이 글이 JEPA 시리즈 전체의 출발점이다. 이번 장은 그 비전 문서가 무엇을 주장하는지를 짧고 명확하게 본다.
이번 장에서 자주 나올 단어들을 미리 풀어두면: 자율 지능(Autonomous Intelligence) = 사람이 매번 지시하지 않아도 스스로 목표를 세우고 행동하는 AI. World Model(세계 모형) = AI가 머릿속에 가진 "세상이 어떻게 굴러가는지"의 내부 표현.
Self-Supervised Learning(SSL, 자기지도 학습) = 사람이 라벨을 달지 않은 데이터로 AI가 스스로 학습 신호를 만드는 방식. 자세한 정의는 3장에서 다룬다.
- 'World Model'이라는 단어가 AI 연구에서 정확히 무엇을 가리키는지 안다
- LeCun의 2022 비전 문서가 어떤 글이고 왜 중요한지 설명할 수 있다
- 그가 제안한 자율 지능 아키텍처의 6개 모듈을 외운다
- 왜 'World Model'이 AI의 6모듈 중 하나로만 등장하는지(다른 5개가 있는 이유) 이해한다
- 이 코스 전체가 LeCun의 비전을 어떻게 따라가는지 지도를 갖는다
Sections
1.1 LeCun이 던진 질문 — "지능이란 무엇인가"
LeCun의 핵심 가설은 한 문장이다: "지능 = 미래를 예측하는 능력".
그가 드는 예시: 갓난아기는 컵을 떨어뜨리면 깨진다는 걸 누가 가르치지 않아도 몇 달 안에 배운다. 아기 머릿속에 "물체는 떨어지고, 단단한 물체는 부딪히면 깨진다"는 작은 모형(World Model)이 형성된다. 이 모형 덕분에 아기는 행동하기 전에 "이걸 떨어뜨리면 어떻게 될까"를 머릿속으로 시뮬레이션할 수 있다.
LeCun의 주장: 진짜 지능을 가진 AI도 이런 모형을 가져야 한다. 단순히 패턴을 외우는 게 아니라, 행동의 결과를 머릿속에서 미리 예측할 수 있어야 한다. 그래서 "World Model"이라는 단어가 그의 비전의 중심에 놓인다.
caveat: 이건 LeCun의 **position(견해)**이다. 경험적으로 "증명된 사실"이 아니다. 같은 시기에 OpenAI·Anthropic 등 다른 연구자들은 "LLM의 스케일을 키우면 결국 추론까지 갈 거다"라는 다른 견해를 갖고 있다. 두 진영의 논쟁이 8장의 주제다.
1.2 2022년의 비전 문서 — 무엇이 적혀 있나
LeCun의 글은 정식 논문이 아니라 position paper(견해 논문)다. 동료 평가를 거치지 않고 OpenReview에 직접 공개. 그 자체로 학술적 결과를 주장하기보다 "우리가 어디로 가야 한다"는 방향을 제시하는 글.
글의 핵심 주장 한 줄: 자율 지능 에이전트를 만들려면 세 가지 요소를 결합해야 한다.
- Configurable predictive world model (설정 가능한 예측형 세계 모형) — 환경의 미래를 시뮬레이션할 수 있는 내부 모형
- Intrinsic motivation (내재 동기) — 외부 보상 없이도 스스로 목표를 만드는 동기 시스템
- Hierarchical joint embedding architectures (계층적 결합 임베딩 아키텍처) — Self-Supervised Learning으로 학습된 표현 공간
이 셋을 합쳐야 한다는 게 그의 메인 메시지. 그리고 그 중 가장 구체적으로 "어떻게 만들지"를 제시한 게 세 번째 — JEPA(Joint Embedding Predictive Architecture)다. JEPA의 정확한 정의는 4장에서 깊이 다룬다.
출처: OpenReview, https://openreview.net/pdf?id=BZ5a1r-kVsf
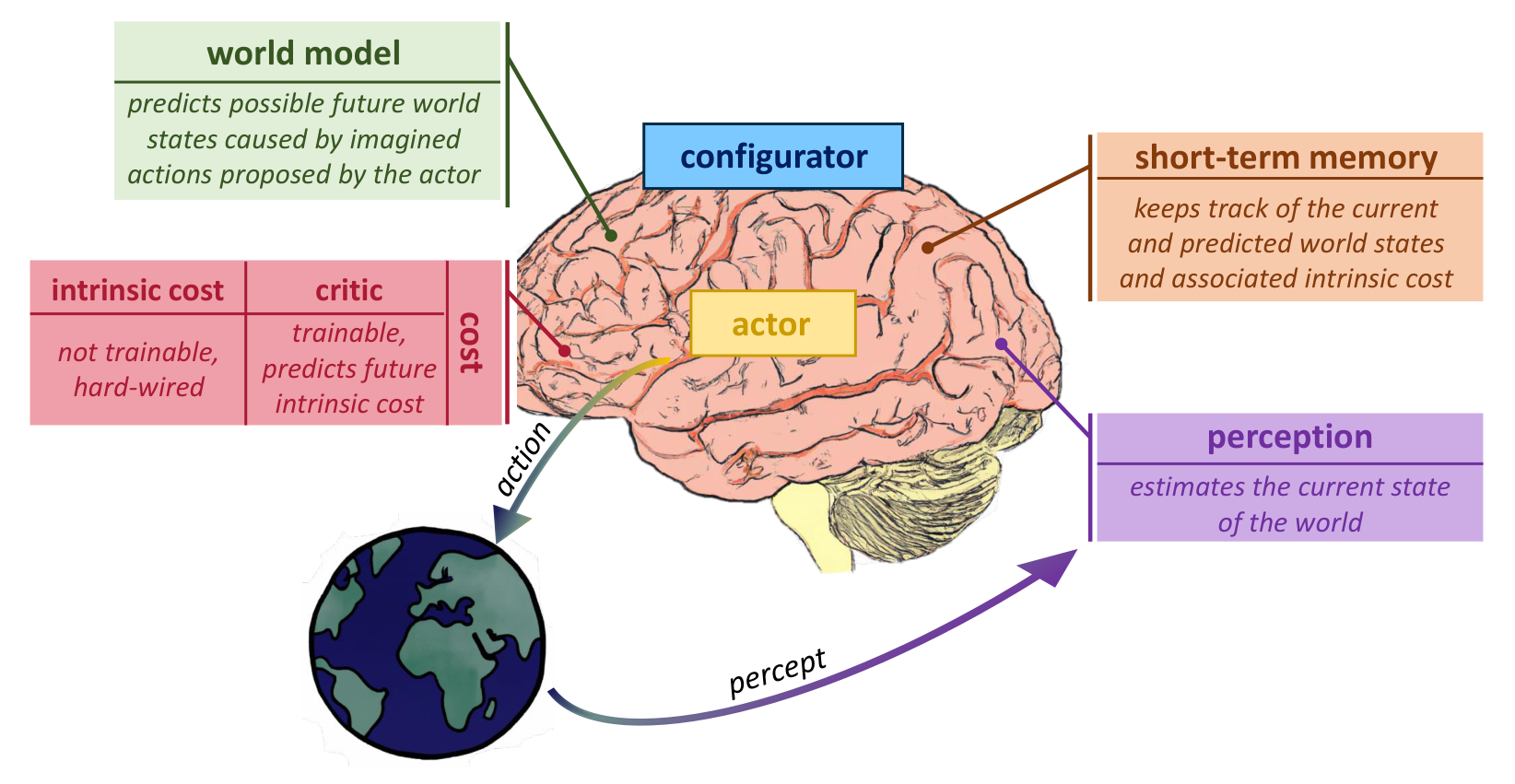
1.3 6개 모듈로 구성된 자율 지능 아키텍처
LeCun이 글에서 그린 자율 지능 에이전트의 청사진은 6개 모듈로 구성된다. 각각이 미분 가능(differentiable, 학습으로 파라미터를 업데이트할 수 있는)한 부품이다.
| 모듈 | 영문 | 하는 일 |
|---|---|---|
| 설정자 | Configurator | 다른 모듈들의 동작 모드를 조정하는 "실행 제어" |
| 지각 | Perception | 카메라·마이크 같은 센서 입력에서 현재 세계의 상태를 추정 |
| 세계 모형 | World Model | 현재 상태와 가능한 행동이 주어졌을 때 미래 상태를 예측 |
| 비용 | Cost | 에이전트가 처한 상태가 얼마나 좋은가/나쁜가를 점수로 |
| 행위자 | Actor | 가능한 행동 시퀀스를 제안 |
| 단기 기억 | Short-term Memory | 지금까지의 세계 상태 이력을 보관 |
흐름: 지각이 현재 상태를 알려주면 → 행위자가 여러 행동 후보를 만들고 → 세계 모형이 "이 행동을 하면 어떻게 될까"를 예측하고 → 비용이 그 미래 상태들을 평가하고 → 가장 좋은 행동을 실행. 단기 기억은 이 과정을 받치고, 설정자는 전체를 조율.
이 6개 모듈 중 World Model 하나만이 "세계가 어떻게 굴러가는지"의 모형이다. 다른 5개는 그 모형을 활용하는 주변 부품. JEPA 시리즈는 이 World Model 부품을 어떻게 만들지의 구체적 답이다.
출처: LeCun 2022 paper §3, Meta AI 블로그 https://ai.meta.com/blog/yann-lecun-advances-in-ai-research/
1.4 왜 다른 모듈이 아니라 World Model이 핵심인가
6개 모듈 중 어느 것이라도 빠지면 자율 지능이 안 된다. 그런데 왜 LeCun(과 이 코스)은 World Model을 특별히 중심에 놓는가?
이유 1 — 모형의 질이 모든 결정의 질을 결정한다. 행위자가 아무리 다양한 행동을 제안해도, 세계 모형이 "그 행동의 결과"를 정확히 예측 못 하면 비용이 잘못된 평가를 한다. 결국 잘못된 행동이 선택된다.
이유 2 — 다른 모듈은 기존 기술로 어느 정도 만들 수 있다. Perception(이미지 인식)은 ResNet·ViT 같은 비전 모델이 잘 한다. Actor(행동 정책)는 강화학습이 다룬다. 단기 기억은 transformer 같은 sequence 모델이 어느 정도. 그러나 World Model — 즉 "세계가 어떻게 굴러가는지"의 학습된 표현 — 은 아직 풀리지 않은 문제다.
이유 3 — World Model 없이는 "계획"이 불가능하다. 사람이 "이걸 먹으면 배 아플 거 같다"고 미리 판단하는 건 머릿속 모형의 시뮬레이션. AI도 그런 능력을 가지려면 모형이 필요. 그래서 LeCun이 보기에 "진짜 추론"의 본질은 World Model의 시뮬레이션이지, LLM의 텍스트 자동완성이 아니다.
이 마지막 문장이 LeCun의 LLM 비판의 핵심이다. 다음 장에서 자세히 본다.
1.5 이 코스의 흐름
1장이 "왜 World Model이 중요한가"의 큰 그림이다. 다음 9개 챕터의 흐름:
- 2장: LeCun이 LLM·Diffusion 등 현재 주류 AI를 왜 비판하는지의 정확한 두 가지 이유를 본다 (Generative vs Predictive).
- 3장: World Model을 학습하는 방법인 Self-Supervised Learning의 역사 — SimCLR → MoCo → BYOL → DINO → MAE → JEPA의 가족 트리.
- 4장: JEPA 아키텍처의 정확한 정의. 두 인코더 + Predictor + 에너지 함수.
- 5장: I-JEPA (2023) — 이미지에 적용한 첫 JEPA.
- 6장: V-JEPA (2024) — 비디오로 확장.
- 7장: V-JEPA 2 (2025) — 1.2B 파라미터 + 로봇 zero-shot 제어. World Model의 첫 실전 데모.
- 8장: Meta가 공개한 물리 추론 벤치마크 — 인간 85-95% vs 모델 chance. 격차의 의미.
- 9장: Generative vs Predictive 논쟁의 풍경 — LeCun vs Sutskever/Karpathy/Sora.
- 10장: 다른 World Model 학파(Dreamer·Genie·Sora·Cosmos)와 JEPA의 위치.
각 장 끝에는 Python 코드 예시 + 면접 평가 + 핵심 정리 카드. 다음 장으로 가자.
다섯 살 아이가 자전거를 배운다. 처음엔 누가 시켜야만 페달을 밟지만, 며칠 지나면 자기 머릿속에 작은 "자전거 모형"이 생긴다. "이 각도로 핸들을 돌리면 이렇게 기울어진다", "이 속도면 안 넘어진다". 이게 아이의 세계 모형이다.
이 모형이 생기는 순간 마법 같은 일이 일어난다. 아이는 행동하기 전에 머릿속에서 미리 시뮬레이션할 수 있다. "여기서 좌회전하면 저 나무에 부딪힐 거 같으니까 우회전하자". 이게 "계획"이다.
LeCun의 주장이 정확히 이거다. 진짜 지능을 가진 AI도 머릿속에 "세상이 어떻게 굴러가는지"의 모형을 가져야 하고, 그 모형으로 행동의 결과를 예측할 수 있어야 한다. JEPA 시리즈는 그 모형을 어떻게 만들지의 구체적 답을 찾으려는 시도다. 이 코스는 그 시도가 어디까지 왔는지의 여행.
LeCun이 제안한 6모듈 아키텍처를 가장 단순한 시뮬레이션으로 그려본다. 진짜 학습은 안 하고 모듈들의 "역할"만 보여준다. 흐름을 이해하는 게 목적.
from dataclasses import dataclass, field
from typing import Callable
# 6 modules from LeCun's 2022 vision paper
@dataclass
class State:
"""A snapshot of the world (perception's output)."""
data: dict = field(default_factory=dict)
@dataclass
class AutonomousAgent:
perception: Callable[[any], State] # sensors → state
world_model: Callable[[State, str], State] # state + action → next state
cost: Callable[[State], float] # state → 'how bad'
actor: Callable[[State], list] # state → candidate actions
short_memory: list = field(default_factory=list)
configurator_mode: str = 'normal'
def step(self, sensor_input):
# 1) Perception
current = self.perception(sensor_input)
self.short_memory.append(current)
# 2) Actor proposes candidate actions
candidates = self.actor(current)
# 3) World Model simulates each candidate's future
# 4) Cost evaluates each predicted future
scored = [
(action, self.cost(self.world_model(current, action)))
for action in candidates
]
# 5) Pick the lowest-cost action
best_action, best_cost = min(scored, key=lambda x: x[1])
return best_action, best_cost
# Toy example — agent picking between 'forward' and 'turn'
agent = AutonomousAgent(
perception=lambda x: State(data={'wall_distance': x}),
world_model=lambda s, a: State(data={
'wall_distance': s.data['wall_distance'] - (1 if a == 'forward' else 0)
}),
cost=lambda s: 100.0 if s.data['wall_distance'] <= 0 else 0.0,
actor=lambda s: ['forward', 'turn'],
)
action, cost = agent.step(sensor_input=1) # wall is 1 step away
print(f'Best action: {action}, predicted cost: {cost}')
# → 'turn' chosen because world_model predicts forward = collision
이 더미 에이전트가 LeCun 아키텍처의 정신을 보여준다. Perception이 상태(벽까지 거리)를 만든다. Actor가 후보(forward·turn)를 제안한다. World Model이 각 후보의 미래를 시뮬레이션한다. Cost가 그 미래를 점수화. 가장 좋은 행동 선택. 실제 JEPA 시리즈가 풀려는 문제는 "world_model 함수를 어떻게 데이터에서 학습할까"다 — 우리가 손으로 적은 게 아니라 비디오에서 자동으로.
✅ 시니어가 보는 것
- 'World Model'을 RL의 environment model 또는 LeCun의 자율지능 모형으로 정확히 구분
- LeCun의 6모듈을 외우고 각 역할을 즉답
- World Model이 다른 모듈과 어떻게 결합되는지 그릴 수 있음
- LLM이 World Model을 "갖고 있다" vs "갖고 있지 않다"의 논쟁을 알고 양쪽 입장 설명 가능
⚠️ 레드 플래그
- 'World Model'을 단순 큰 모델(large model)과 혼동
- LeCun의 비전을 "LLM 반대"로만 외우고 6모듈 모름
- World Model = 게임 시뮬레이터 정도로만 이해
- Position paper와 peer-reviewed 논문을 같은 무게로 다룸
🎤 예상 인터뷰 질문
- LeCun이 말하는 World Model의 정의를 한 문장으로 말해 주세요
- 그가 제안한 6모듈 아키텍처를 그려보세요
- 왜 그가 'LLM이 만든 답은 진짜 추론이 아니다'라고 주장하나요?
Key Takeaways
지능 = 예측
LeCun의 한 줄 가설. JEPA 전체의 출발점.
World Model
AI가 머릿속에 가진 "세상이 어떻게 굴러가는지"의 모형.
Vision paper 2022
v0.9.2, 2022-06-27, OpenReview. Position paper.
6 모듈 아키텍처
Configurator · Perception · World Model · Cost · Actor · Short-term Memory.
Differentiable
6 모듈 모두 미분 가능 = 학습으로 파라미터 갱신.
Position vs Proof
LeCun의 주장은 견해다. 경험적 증명 아님.
JEPA = World Model을 만드는 방법
이 코스 전체가 그 방법의 진화.
다음 9장의 지도
이론 → 시리즈(I·V·V2) → 평가 → 논쟁 → 다른 학파.