WELCOME — DIRECF.GITHUB.IO 







direct fun, deep study
AI 시대를 살아가며 공부한 것들과 가끔의 사적인 단상. 좌측 카테고리에서 영역별로 글을 탐색할 수 있다.
최신 글
MULTIMODAL AI
Spatial VLM의 진화 — 대표 논문 10편으로 읽는 공간추론 연구의 흐름
SpatialVLM(2024)에서 GR3D·VLM-3R(2026)까지, vision-language model이 '공간을 추론'하게 된 과정을 대표 논문 10편으로 해부한다. 진단(BLINK) → 데이터 합성(SpatialVLM) → region·depth 아키텍처(SpatialRGPT·SpatialBot) → 비디오 벤치마크(VSI-Bench·OmniSpatial) → 정신적 시뮬레이션(APC) → depth-native VLM(DepthVLM) → verifiable RL(Smooth Operator) → reconstruction 융합(GR3D)으로 이어지는 흐름을, '언어 토큰과 연속적 3D 기하 사이의 표상 불일치(representational mismatch)'라는 축으로 관통한다. 각 전환의 필연을 논문 figure·mermaid 개념도·실행 가능한 코드와 함께 해부하는 연구자·면접 대비 advanced 10챕터.
AI ENGINEERING
Loop Engineering — 프레임워크에서 루프, 그리고 그래프로 (대표 논문 13편)
AutoGPT식 monolithic 에이전트 프레임워크에서 "에이전트는 결국 루프다"라는 harness 관점으로, 다시 LangGraph식 명시적 그래프 오케스트레이션으로 넘어가는 흐름을 대표 논문·에세이 13편으로 추적한다. ReAct·Reflexion·Voyager·Building Effective Agents·Tree of Thoughts·ReWOO·LLMCompiler·DSPy·LangGraph까지, framework→loop→graph 진화사로 2026 프로덕션 에이전트를 실제로 어떻게 짜는지 배운다.
COMPUTER VISION
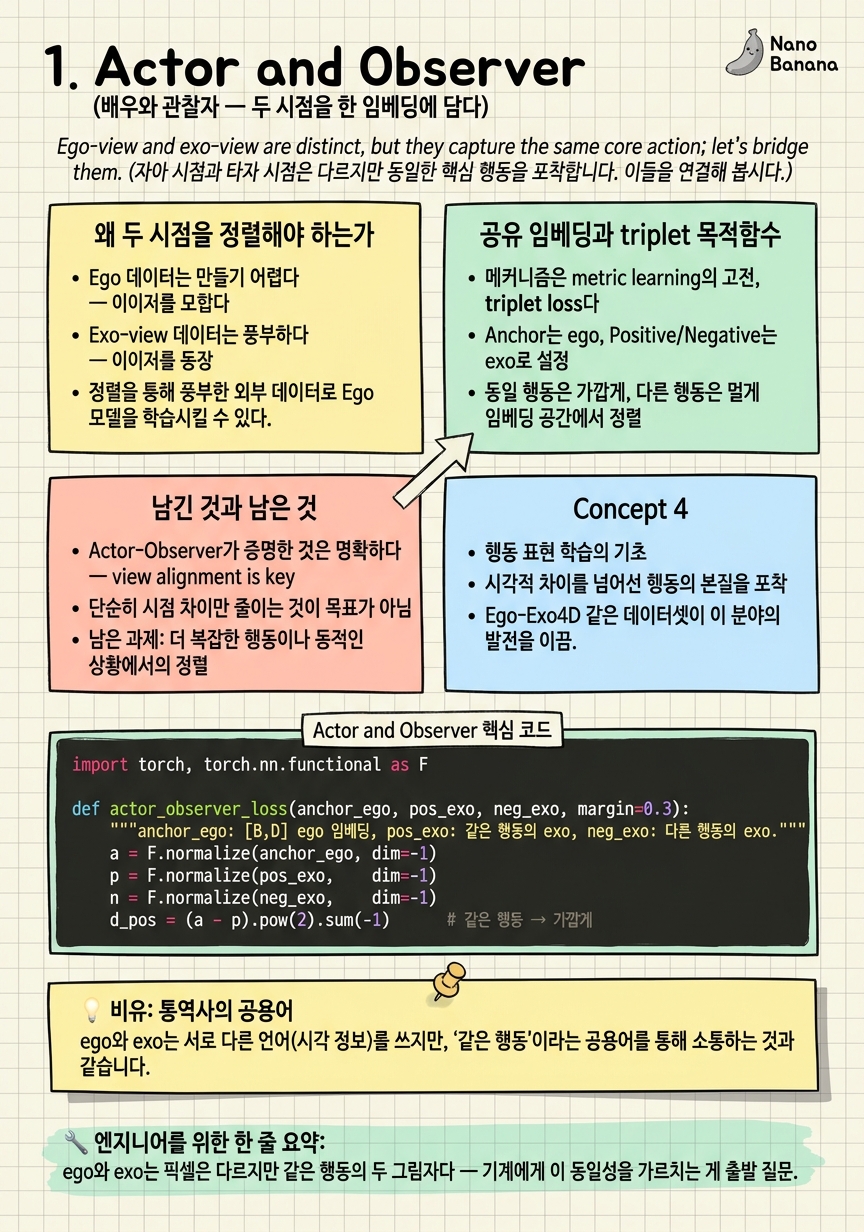
에고-엑소 시점 일관성 — 두 시점을 하나로 잇는 연구의 흐름 (대표 논문 10편)
1인칭(ego)과 3인칭(exo) — 같은 사건의 두 시점을 '일관되게' 잇는 연구가 8년간 어떻게 깊어졌는지의 흐름과 insight를 10편으로 정리한다. 데이터셋이 아니라 방법론에 집중: 표현 정렬(Actor-Observer·Ego-Exo·AE2·BYOV·Rosetta Stone) → 객체 대응(ObjectRelator·O-MaMa·CCMP) → 시점 생성(Exo2Ego) → 추론 통합(View-GRPO). '일관성의 정의가 feature→시간→픽셀→생성→추론으로 점점 깊어진 역사'를 축으로, 각 전환의 필연을 논문 figure·개념 다이어그램과 함께 해부하는 연구자·면접 대비 advanced 10챕터.
그 외 글
MULTIMODAL AI
실시간 VLM 비용 최적화 — 단계별 이벤트 탐지 논문 10편
PHYSICAL AI
COMPASS & Cross-Embodiment Mobility — 하나의 정책으로 모든 로봇을 움직이다
PHYSICAL AI
NVIDIA Physical AI Map — Omniverse·Cosmos·Isaac·GR00T 전체 지도
PHYSICAL AI
GR00T & NVIDIA Physical AI 2026 — GR00T는 데이터로 navigation과 manipulation을 다 먹는가
COMPUTER VISION
Ego-Exo 연구 — 크로스뷰 학습부터 논문 작성까지
COMPUTER SCIENCE
AI 엔지니어를 위한 백엔드 & Ops
CLOUD / INFRA
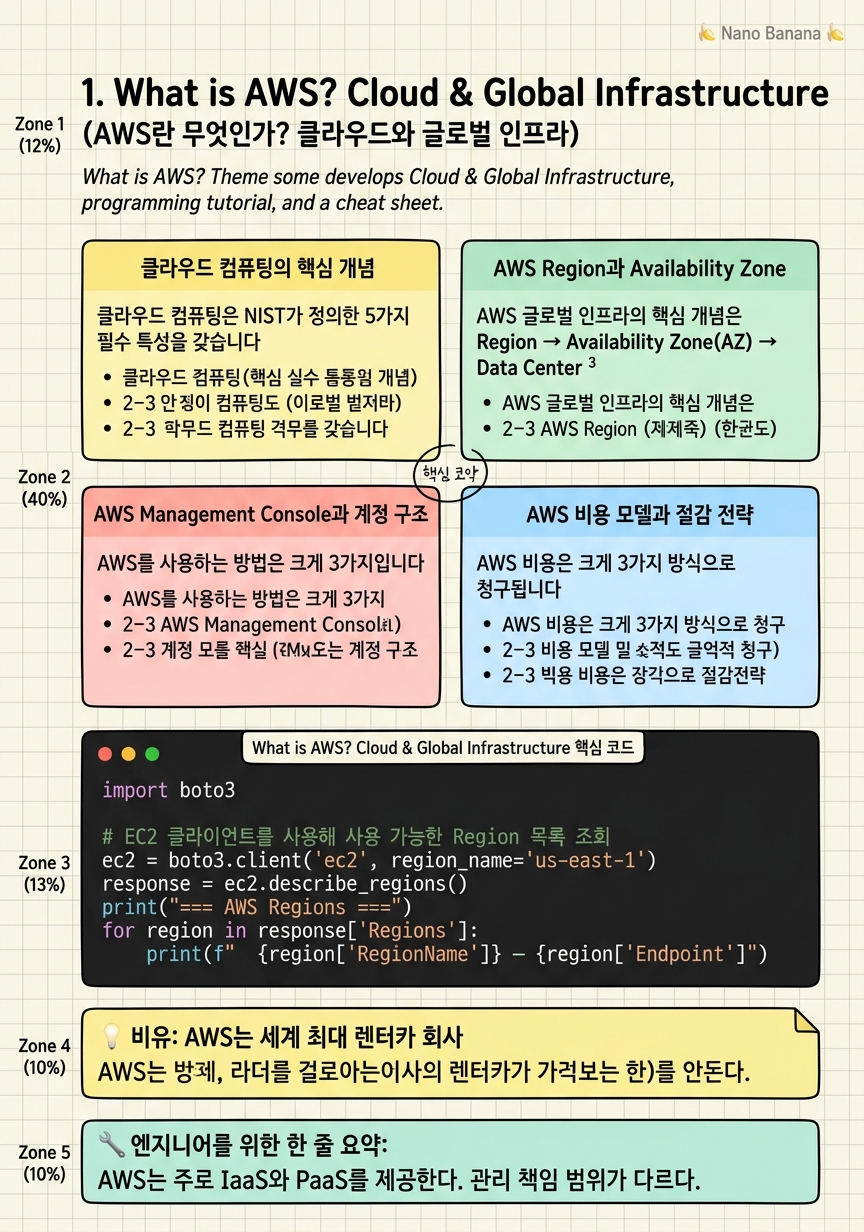
AWS 기초 완전 정복 — S3·EC2·VPC·Lambda부터 실전 아키텍처까지