Other World Model Schools and the Future
다른 World Model 학파와 미래
JEPA만이 World Model 연구가 아니다. Ha & Schmidhuber(2018), DeepMind의 Dreamer V1-V3, Genie, OpenAI Sora, NVIDIA Cosmos — 각각의 학파와 JEPA의 비교. 2026년 6월 현재 영향력 정직하게.
Overview
World Model은 LeCun과 JEPA만의 주제가 아니다. 여러 학파가 다른 접근으로 같은 목표를 추구한다. 이번 마지막 장은 그 풍경을 본다.
이번 장은 deep research에서 "VLA-JEPA 및 다른 학파의 정확한 비교 수치"가 일부 검증 안 됨을 인지하고, 검증된 핵심만 다룬다. 정확한 비교 벤치마크 수치는 caveat과 함께 제시.
- Ha & Schmidhuber의 2018 World Models 논문 위치를 안다
- Dreamer 시리즈의 핵심 발상과 RL 적용을 안다
- Genie의 'foundation world model' 접근을 안다
- Sora·NVIDIA Cosmos의 generative world model 라인을 안다
- JEPA가 이 풍경에서 어디 위치하는지 그릴 수 있다
Sections
10.1 Ha & Schmidhuber 'World Models' (2018) — 원조
World Model이라는 단어가 AI 학계에서 본격적으로 쓰이게 된 결정적 논문: David Ha & Jürgen Schmidhuber, "World Models" (2018).
핵심 발상: 강화학습 에이전트가 환경을 직접 학습하기 전에, 환경의 모형(World Model)을 먼저 학습한다. 그 다음 그 모형 안에서 "머릿속으로" 시뮬레이션하며 정책 학습.
구조:
- Vision (V): VAE로 관측을 압축 (잠재 변수)
- Memory (M): RNN으로 "이 상태에서 이런 행동을 하면 다음 상태가 어떨까" 학습
- Controller (C): 작은 신경망으로 정책 결정
의의: "World Model을 학습한 뒤 그 안에서 정책을 키운다"는 패턴을 정립. 이후 모든 model-based RL의 표준.
JEPA와의 차이:
- Ha 2018: RL용. 게임·시뮬레이터 환경. VAE 기반 (생성형).
- JEPA: SSL용. 일반 비디오. 비생성형.
두 접근은 다른 도메인을 다루지만 "World Model 학습"의 기본 정신은 공유.
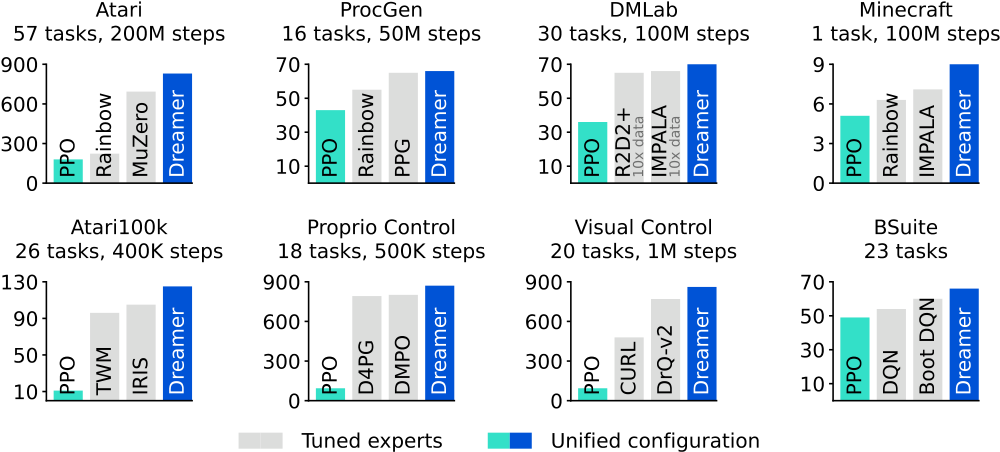
10.2 DeepMind Dreamer V1-V3
Ha 2018의 발상을 DeepMind가 발전시킨 게 Dreamer 시리즈.
Dreamer V1 (2019): latent dynamics model을 학습해 그 안에서 정책 학습. Atari·DeepMind Control Suite.
Dreamer V2 (2020): 카테고리 잠재 변수 도입. Atari 100% normalized 점수 달성.
Dreamer V3 (2023, arXiv 2301.04104): 단일 모델로 150개 이상의 도메인에서 인간 수준. Atari·Crafter·Minecraft 등 매우 다양한 환경. 같은 하이퍼파라미터로 모든 환경에 적용 — "general world model"의 첫 데모.
핵심 차이 vs JEPA:
- Dreamer는 RL 환경 내(시뮬레이터). JEPA는 자연 비디오.
- Dreamer는 픽셀 재구성을 손실에 포함 (반-생성). JEPA는 완전 비생성.
- Dreamer는 "보상 + 다음 상태"를 명시적으로 예측. JEPA는 그 위에 V-JEPA 2-AC로 액션을 추가.
현재 영향력: Dreamer V3는 RL 분야에서 매우 강한 베이스라인. JEPA가 "일반 시각"이라면 Dreamer는 "환경 RL"의 World Model 표준.
출처: arXiv 2301.04104 (Dreamer V3).
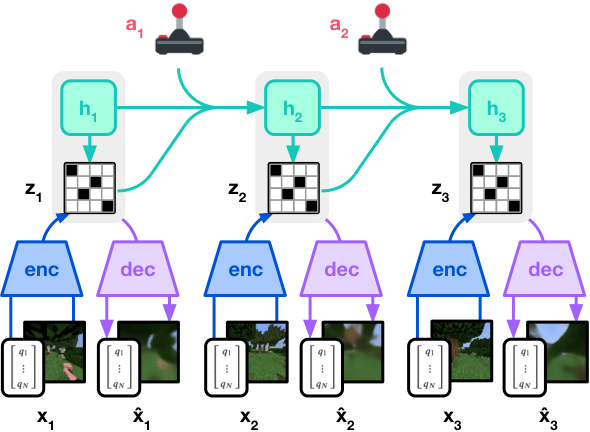
10.3 DeepMind Genie — Foundation World Model
Genie(2024, DeepMind): "수십만 개의 인터넷 게임 영상을 학습해 새로운 상호작용 가능 환경을 생성"의 모델.
핵심 발상: 비디오만 보고 "플레이어 액션 → 다음 프레임"의 관계를 자동 학습. 라벨 없이.
Genie 1: 2D 게임 영상. 입력: 한 장면. 액션을 주면 그 액션에 맞는 다음 프레임 생성.
Genie 2 (2024-12): 3D 환경으로 확장. "한 이미지에서 1분 단위의 상호작용 가능 환경 생성". Foundation world model이라 명명.
JEPA와의 차이:
- Genie: Generative. 픽셀까지 만든다.
- JEPA: Predictive. 임베딩만.
- Genie: 게임·상상 환경 생성에 강점.
- JEPA: 자연 영상의 추상 이해에 강점.
의의: "한 이미지에서 상호작용 가능 환경을 만든다"는 발상은 Sora보다 더 명시적으로 "World Model". 다만 픽셀 시뮬레이션의 한계는 그대로.
출처: Wikipedia Genie (world model).
10.4 OpenAI Sora와 NVIDIA Cosmos
OpenAI Sora (2024-02): 텍스트로부터 1분 영상 생성. OpenAI가 "world simulator"라 명명. 자세한 건 9장 참고. Generative.
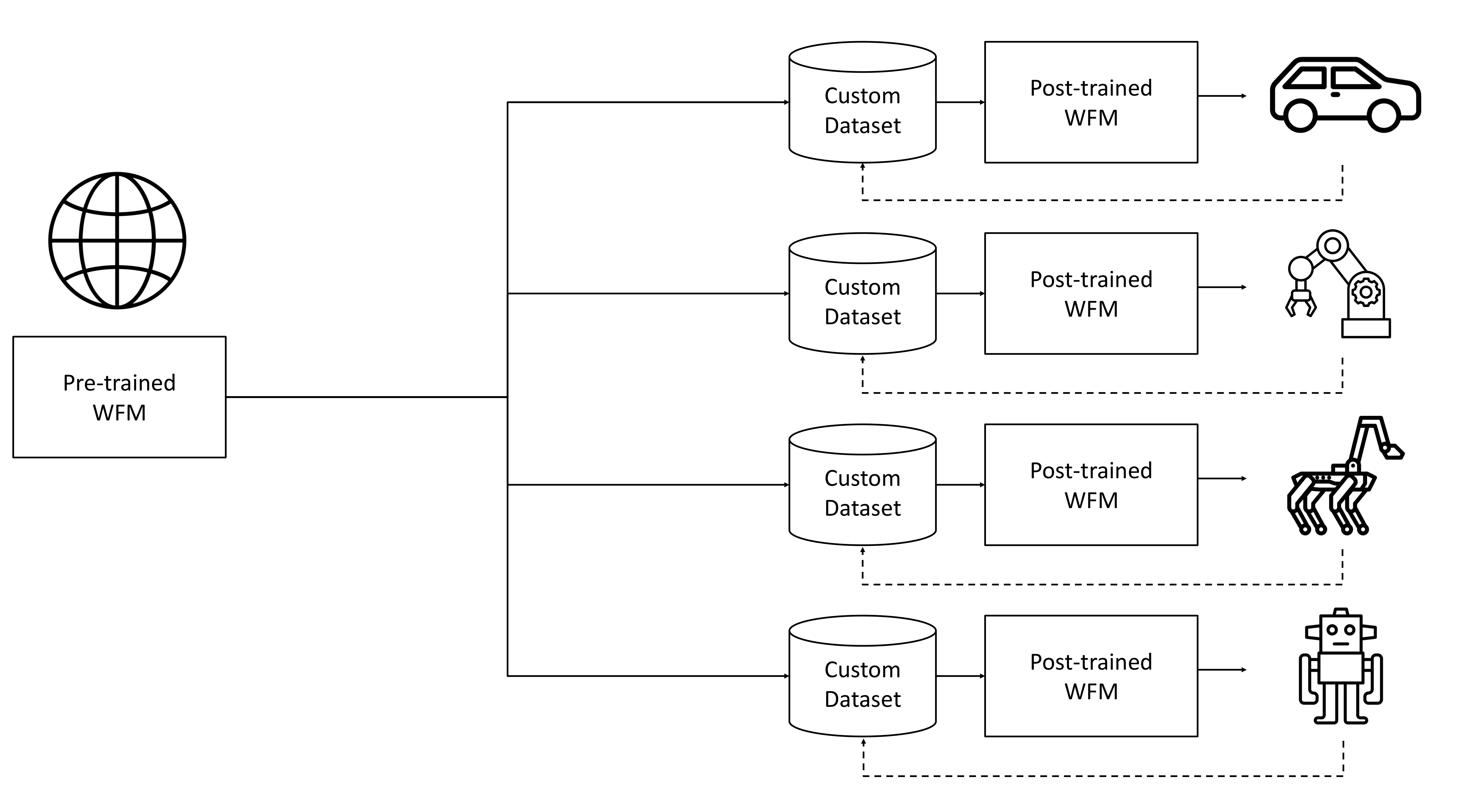
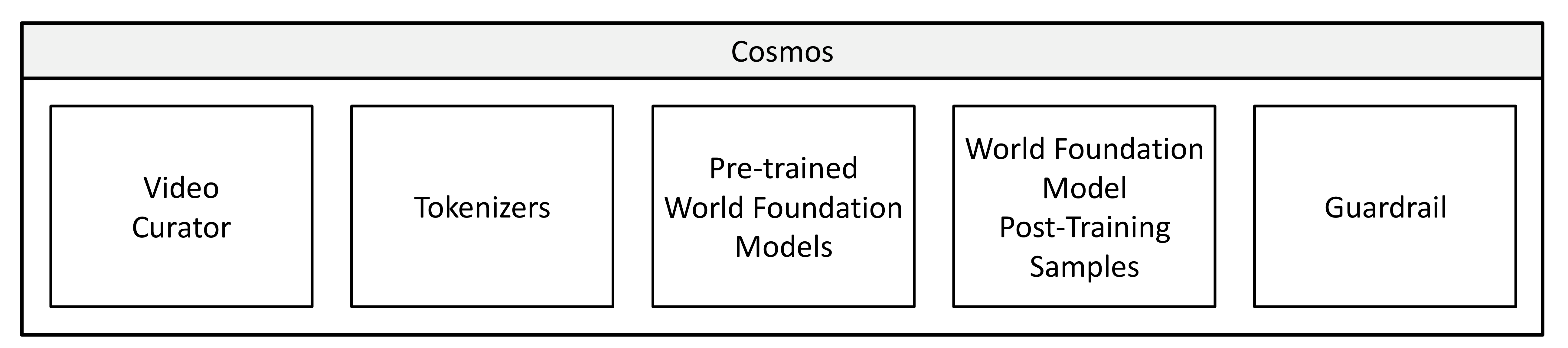
NVIDIA Cosmos (2025-01, arXiv 2501.03575): "Cosmos World Foundation Model Platform for Physical AI". NVIDIA가 자율주행·로봇용으로 발표.
Cosmos의 두 갈래:
- Cosmos-1.0-Diffusion: 비디오 생성형. Sora 류.
- Cosmos-1.0-Autoregressive: 토큰 단위 자기회귀.
의의: NVIDIA는 자율주행·로봇 시뮬레이션 자원을 World Model로 패키징해 산업 도입을 노림. 학술적 새로움보다 "산업 적용"의 실용 사례.
JEPA와의 비교:
- Cosmos: 픽셀 생성. 시각적 확인 가능한 시뮬레이션.
- JEPA: 임베딩만. 사람이 "시뮬레이션 결과"를 볼 수 없음.
- 두 접근 모두 자율주행·로봇 시뮬레이션을 노리지만 본질이 다름.
출처: arXiv 2501.03575.
10.5 World Model 풍경의 종합 — 그리고 본 코스의 마무리
현재 World Model 풍경:
| 학파 | 대표 모델 | 접근 | 적용 도메인 |
|---|---|---|---|
| Meta / LeCun | I-JEPA, V-JEPA, V-JEPA 2 | 비생성 SSL | 자연 비디오, 로봇 |
| DeepMind RL | Dreamer V1-V3 | 반-생성 RL | 게임·시뮬레이터 |
| DeepMind Foundation | Genie 1·2 | 생성 (foundation) | 상호작용 환경 |
| OpenAI | Sora | 생성 (diffusion) | 비디오 생성 |
| NVIDIA | Cosmos | 생성 (두 갈래) | 산업 시뮬레이션 |
| 원조 | Ha & Schmidhuber 2018 | VAE+RNN | RL 게임 |
각 진영의 현재 영향력 (2026-06 정직 평가):
- Meta JEPA: 학계 활발한 연구. Meta 외 산업 채택은 제한적. 자율주행·로봇 분야에서 신호 시작.
- DeepMind Dreamer: RL 분야의 강한 베이스라인. 학계 인용 활발.
- Genie: 새로움 인상적. 실용 적용은 초기.
- Sora: 상업적 화제성 압도. "진짜 World Model"의 학술 가치는 논쟁 중.
- NVIDIA Cosmos: 산업 도입 노린 패키지. 자율주행 회사들이 검토 중.
caveat: 위 "영향력 평가"는 본 deep research에서 정량 지표(인용 수·산업 채택 통계)로 검증 안 됨. 대체적 학계 풍경의 묘사.
본 코스를 마치며: 10장에 걸쳐 LeCun의 비전 → JEPA 시리즈 → 한계 → 다른 학파를 봤다. 이 분야는 2026년 현재 가장 활발한 AI 연구 전선 중 하나다. 어느 학파가 이길지는 정해지지 않았다. 본 코스를 끝낸 학습자가 갖고 갈 것: (1) 정확한 사실의 토대, (2) 양쪽 진영을 공정히 정리할 수 있는 자세, (3) 새 결과가 나올 때마다 평가할 수 있는 도구. 이 세 가지가 본 분야의 미래를 자기 눈으로 따라갈 수 있게 한다.
한 산의 정상(인간 수준 World Model)에 여러 길이 있다.
(A) JEPA 길: 추상화된 의미 표현으로 직접 정상에. LeCun 일행이 개척 중. (B) Sora 길: 픽셀 시뮬레이션의 정교화로. OpenAI·DeepMind 일행. (C) Dreamer 길: 시뮬레이터 환경 안에서 RL로. DeepMind RL팀. (D) Cosmos 길: 산업 적용으로 검증하며. NVIDIA.
1990년대 인터넷 등장 때도 이랬다. 한 진영(웹 vs Gopher vs FTP)이 길이라고 단언한 사람들이 모두 부분적으로 옳았고, 결국 웹이 표준이 됐다. 그러나 그게 끝이 아니었다 — 모바일 앱·SNS·블록체인 등 새 길이 계속 나타났다.
World Model도 마찬가지일 가능성. 2026년 6월의 "승자"가 영원한 승자가 아니다. 본 코스의 학습자는 풍경 전체를 알고, 새 학파가 등장할 때마다 "이게 LeCun 식인가 OpenAI 식인가 또는 새 식인가"를 빠르게 분류할 수 있어야 한다.
끝. 잘 끝마쳤다.
본 코스를 마치며 — 각 학파의 World Model을 한 줄로 비교하는 의사 코드. 각 함수의 'predict_next'가 그 학파의 본질.
# ============== Different schools, same goal: predict the future ==============
# Ha & Schmidhuber 2018 — VAE + RNN
def ha_predict_next(state, action, vae, rnn):
z = vae.encode(state)
z_next = rnn(z, action)
return vae.decode(z_next) # pixels (lossy)
# Dreamer V3 — RSSM (Recurrent State Space Model)
def dreamer_predict_next(state, action, rssm):
deterministic, stochastic = rssm.encode(state)
next_det, next_stoch = rssm.step(deterministic, stochastic, action)
return rssm.decoder(next_det, next_stoch) # pixels + reward
# Sora — Diffusion in pixel space
def sora_predict_next(text_prompt, prev_frames, diffusion):
return diffusion.sample(condition=(text_prompt, prev_frames)) # pixels
# Genie 2 — Foundation video model
def genie_predict_next(scene_image, action, genie):
return genie.unroll(scene_image, [action], steps=60) # 1 minute of pixels
# V-JEPA 2-AC — Predictive (LeCun school)
def vjepa2_predict_next(video, action, encoder, action_transformer):
s = encoder(video).detach()
return action_transformer(s, action) # embedding only
# NVIDIA Cosmos — two flavors
def cosmos_predict_next_diffusion(state, action, model):
return model.diffusion(state, action) # pixels
def cosmos_predict_next_autoregressive(state, action, model):
return model.next_token(state, action) # discrete tokens
# 각 함수의 반환 타입이 학파의 본질:
# pixels (생성형) vs embedding (비생성형) vs tokens (자기회귀)
# 이 trade-off 위에 모든 World Model 연구가 서 있다.
한 자리에 모아 보면 각 학파가 무엇을 "예측"하는지가 명확하다. Ha·Dreamer·Sora·Genie·Cosmos diffusion은 픽셀, Cosmos autoregressive는 토큰, V-JEPA 2-AC는 임베딩. 각각이 다른 trade-off — 시각 확인 vs 추상 학습 효율, 데이터 효율 vs 일반화. 본 분야의 미래 5년이 어느 trade-off가 진짜 World Model로 가는 길인지를 결정할 것이다.
✅ 시니어가 보는 것
- Ha 2018·Dreamer V3·Genie 1·2·Sora·NVIDIA Cosmos·JEPA 시리즈 모두 안다
- 각 학파의 본질적 차이(예측 대상·도메인) 즉답
- JEPA의 위치를 풍경에서 정확히 가리킴
- 한 학파의 fan이 아닌 풍경 전체의 객관 평가
⚠️ 레드 플래그
- JEPA만 알고 다른 학파 모름
- Dreamer를 "옛날 거"로 무시
- Sora·NVIDIA Cosmos를 마케팅 그대로 옮김
- 각 학파의 영향력을 정량 근거 없이 단정
🎤 예상 인터뷰 질문
- JEPA·Dreamer·Genie·Sora의 핵심 차이를 각각 한 문장으로
- 당신 회사가 자율주행에 World Model을 도입한다면 어느 학파를 보겠습니까?
- 2026년 현재 어느 학파가 가장 영향력 있다고 보십니까? 근거는?
Key Takeaways
Ha 2018 원조
VAE+RNN. RL용 World Model의 시작.
Dreamer V3 (2023)
150+ 도메인 인간 수준. RL의 강력 베이스.
Genie (DeepMind)
Foundation world model. 픽셀 생성.
Sora
텍스트→비디오. OpenAI 'world simulator'.
NVIDIA Cosmos
산업 적용 패키지. 두 갈래 (diffusion + AR).
JEPA의 위치
비생성 자연 비디오. 다른 학파와 본질 차이.
영향력 미정
어느 학파가 이길지 2-3년 결정.
본 코스의 끝
정확한 사실 + 공정한 풍경 + 새 결과 평가 도구.