Self-Supervised Learning의 진화
SSL 가족 트리 — SimCLR에서 JEPA까지
JEPA는 갑자기 등장한 게 아니라 Self-Supervised Learning(SSL)이 5년간 진화한 결과다. SimCLR(2020) → MoCo → BYOL → DINO → MAE → JEPA의 흐름을 따라가면 JEPA가 왜 그 모양인지 자연스럽게 보인다.
Overview
JEPA가 "갑자기 LeCun이 만들어낸 새 아이디어"는 아니다. Self-Supervised Learning(SSL)이라는 5년에 걸친 연구 흐름의 자연스러운 다음 단계다. 이번 장은 SSL 가족 트리 — SimCLR → MoCo → BYOL → DINO → MAE → JEPA — 의 흐름을 본다. 각 단계가 어떤 문제를 풀었고, 다음 단계가 어떤 한계에 답했는지.
이 흐름을 따라가면 JEPA의 디테일(두 인코더, predictor, target block 등)이 "왜 그렇게 설계됐는지"가 자연스럽게 풀린다.
- Self-Supervised Learning(SSL)의 정확한 정의와 Supervised·Unsupervised와의 차이를 안다
- SimCLR·MoCo로 대표되는 Contrastive learning을 설명할 수 있다
- BYOL·DINO의 'Non-contrastive'가 무엇이고 왜 중요한지 안다
- MAE (Masked Autoencoder)와 JEPA의 차이(생성형 vs 비생성형)를 구분한다
- JEPA가 SSL 가족 트리에서 어디 위치하는지 그릴 수 있다
Sections
3.1 Self-Supervised Learning이란
AI 학습 패러다임의 분류:
- Supervised Learning(지도 학습): 사람이 라벨(고양이/개)을 단 데이터로 학습. 예: ImageNet 분류.
- Unsupervised Learning(비지도 학습): 라벨 없음, 군집화·차원 축소 등.
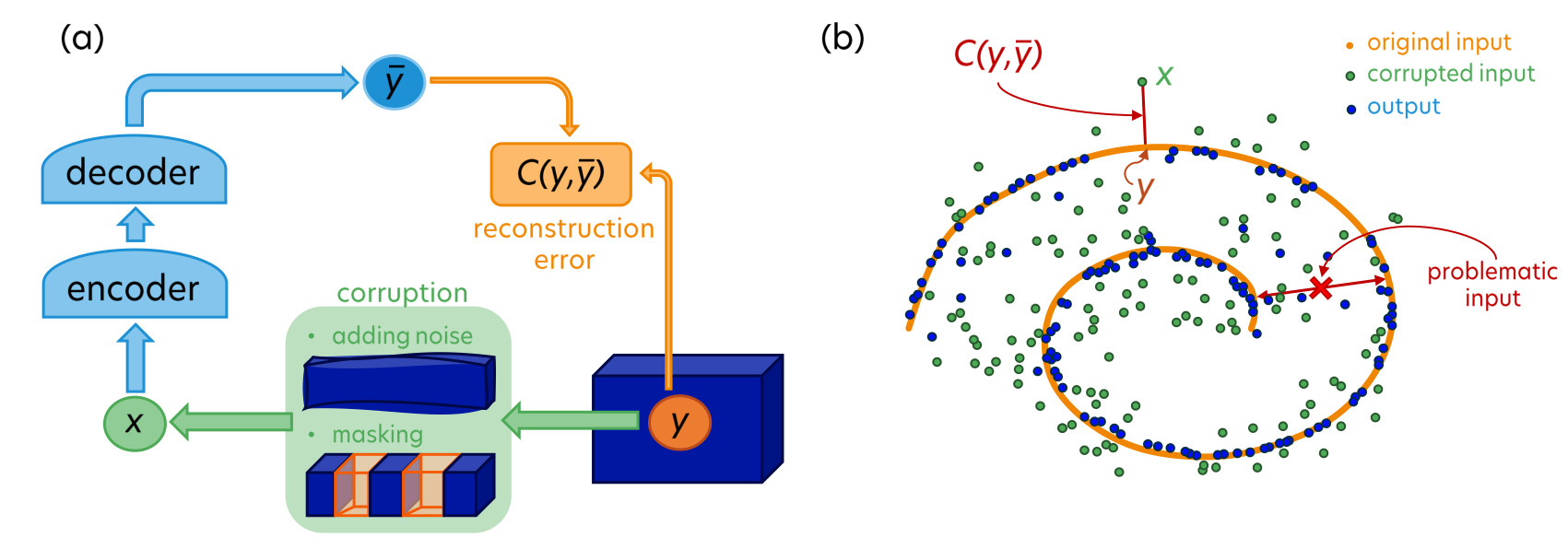
- Self-Supervised Learning(자기지도 학습): 라벨이 없지만 데이터 자체로부터 학습 신호를 만들어낸다. 예: 문장의 일부를 가리고 "가린 단어를 맞추기"(BERT), 이미지 일부를 가리고 "가린 패치를 맞추기"(MAE).
왜 SSL이 중요한가: 라벨 단 데이터는 비싸다. 인터넷에 영상·이미지·텍스트는 무한이지만 "고양이/개" 라벨을 단 데이터는 한정. SSL은 라벨 없는 무한 데이터를 학습 자원으로 바꾼다.
AI 진영 전체가 SSL에 베팅해 왔다. GPT 시리즈도 SSL의 한 형태(next-token prediction). 비전에서도 SSL이 2020년 이후 대세. JEPA는 이 SSL 흐름의 한 줄기다.
3.2 SimCLR과 MoCo — Contrastive Learning의 시작 (2020)
비전 SSL의 첫 큰 흐름은 Contrastive Learning(대조 학습).
SimCLR(Hinton 팀, 2020): 한 이미지에 두 가지 augmentation(자르기·색 변경·회전 등)을 적용해 두 "뷰"를 만든다. 두 뷰는 같은 이미지에서 왔으니까 임베딩이 비슷해야 함(positive pair). 다른 이미지의 뷰와는 멀어야 함(negative pair). 이 "가깝게 + 멀게"를 동시에 학습.
MoCo(Facebook AI, 2020): SimCLR이 negative pair를 만들려면 거대한 배치가 필요한데(메모리 부담), MoCo는 "momentum encoder" + queue로 효율적으로 negative를 모음.
한계: Contrastive는 negative pair가 본질. 그러나 negative를 "잘 고르는" 게 어렵다. 또한 augmentation에 강하게 의존 — 손으로 "이 변환들로 같다고 가르치자"를 설계해야 함. 비전엔 잘 통하지만 다른 도메인엔 일반화 어려움.
JEPA와의 관계: I-JEPA는 명시적으로 "hand-crafted augmentation에 의존하지 않는다"를 자기 차별점으로 제시한다. Contrastive의 이 한계가 다음 단계를 낳았다.
3.3 BYOL과 DINO — Non-contrastive의 발견 (2020-2021)
Contrastive의 한계를 풀려는 시도가 Non-contrastive learning.
BYOL (DeepMind, 2020-06): "Bootstrap Your Own Latent". 충격적 발견 — negative pair 없이도 학습이 된다. 두 네트워크(online + target)를 가지고 한 쪽이 다른 쪽을 "따라가게" 함. target network는 online의 EMA(지수이동평균)로 천천히 업데이트.
당시 학계가 충격받음. 왜냐하면 "negative 없이는 모델이 모든 입력에 같은 임베딩을 뱉는 함정(representation collapse)에 빠진다"는 게 정설이었기 때문. BYOL은 EMA가 그 함정을 막아준다는 걸 보임.
DINO (Meta AI, 2021): "Self-Distillation with No Labels". BYOL의 발상에 student-teacher distillation을 결합. ViT(Vision Transformer)와 잘 맞아 인기. "DINO 임베딩"이 곳곳에 쓰임 — 이미지 검색, 분류, segmentation.
JEPA와의 관계: JEPA의 "두 인코더 (sx, sy)" 구조가 BYOL/DINO의 "online-target" 구조의 직접적 후손. EMA로 target encoder를 천천히 업데이트하는 트릭도 그대로 계승. JEPA는 여기에 "predictor"를 추가한 것.
3.4 MAE — Masked Autoencoder (2021)
또 다른 SSL 줄기는 Masked Autoencoder(MAE) (He, Chen et al., Meta AI, 2021-11).
발상: BERT가 텍스트에서 "단어 일부를 가리고 맞추기"로 성공했으니 이미지도 같이 — "패치 일부를 가리고 픽셀로 맞추기". 인코더가 보이는 패치만 인코딩, 디코더가 가려진 패치의 픽셀을 재구성.
ViT-Large + 75% 마스크가 충격적으로 잘 됨. ImageNet linear probing 84%+ 달성. 비전 SSL의 새 표준이 되는 듯했다.
JEPA가 보는 MAE의 문제: MAE는 픽셀을 재구성한다. 즉 generative. 2장에서 본 LeCun의 두 비판이 정확히 적용 — unpredictable detail(텍스처·노이즈)를 모두 예측해야 함. 결과적으로 "고품질 표현"을 학습하긴 하지만, JEPA 입장에선 "불필요한 디테일에 학습 신호를 낭비".
I-JEPA = MAE를 비생성으로 다시 만든 것. MAE는 가려진 패치의 픽셀을 예측. I-JEPA는 가려진 패치의 임베딩을 예측. 이 한 줄이 차이의 본질.
3.5 SSL 가족 트리에서 JEPA의 위치
한 그림으로 정리.
Self-Supervised Learning (SSL)
│
┌────────────────┬─────────┴─────────┬──────────────┐
│ │ │ │
Contrastive Non-contrastive Masked-Generative Hybrid
│ │ │ │
SimCLR'20 BYOL'20 MAE'21 (DINOv2'23)
MoCo'20 DINO'21 SimMIM'21 ...
│ │ │
└────────────────┼───────────────────┘
│
I-JEPA'23 ← 비생성 + multi-target masking
│
V-JEPA'24 ← 시간축 추가
│
V-JEPA 2'25 ← 1.2B 파라미터 + 액션
JEPA의 정확한 위치: BYOL/DINO의 비대조 학습 정신 + MAE의 마스킹 발상 + 픽셀 대신 임베딩 예측. 세 흐름의 융합.
그리고 JEPA만의 추가:
- Predictor 모듈을 명시적으로 도입 (BYOL의 predictor와 비슷하지만 더 큰 역할)
- 잠재 변수 z의 가능성을 처음부터 형식화
- Energy-based 프레이밍 — E(x,y,z) = D(sy, Pred(sx,z))
이 셋이 더해져 JEPA가 만들어진다. 4장에서 이 구조를 정확히 풀어본다.
외국어를 사전 없이 혼자 배운다고 치자. 네 가지 방법이 있다.
(A) Contrastive: 같은 단어의 다른 발음 두 개를 "같다", 다른 단어의 발음과 "다르다"고 자기 자신에게 가르친다. 같은 것끼리 가깝게, 다른 것끼리 멀게. SimCLR·MoCo가 이 방식.
(B) Non-contrastive: "다른 것" 비교 없이, 같은 단어의 다른 발음 두 개를 들으면 "이 둘은 같은 표현을 갖는 게 맞다"고만 가르친다. BYOL·DINO. 충격적이게도 "다른 것" 없이도 잘 됨.
(C) Masked Autoencoder: 한 문장의 단어 일부를 가리고 "가린 단어의 발음을 정확히 맞춰라". 픽셀(소리) 단위 재현이 목표. MAE.
(D) JEPA: 한 문장의 일부를 가리고 "가린 부분의 의미를 맞춰라". 정확한 발음 아니어도 됨. "이 자리엔 음식 관련 단어가 올 거다" 수준의 임베딩만 맞으면 OK. JEPA의 발상.
(C)와 (D)의 차이가 결정적이다. (C)는 "카멜레온"인지 "카멜릴리언"인지의 미세 발음까지 다 맞춰야 한다. (D)는 "동물 이름이 올 자리" 수준으로도 충분. JEPA가 unpredictable detail을 자연스럽게 버리는 비결이 이거다.
Contrastive (SimCLR 스타일) · Non-contrastive (BYOL 스타일) · Masked (MAE 스타일) · JEPA 의 손실 함수 4개를 한 자리에 적어 비교한다. 각 한 줄이 그 방법의 본질.
import torch
import torch.nn.functional as F
# ============== (A) SimCLR / Contrastive loss ==============
def simclr_loss(z1, z2, temperature=0.1):
"""Positive pair: (z1[i], z2[i]). Negative: all others."""
z1 = F.normalize(z1, dim=-1)
z2 = F.normalize(z2, dim=-1)
sims = z1 @ z2.T / temperature # cosine sim matrix
labels = torch.arange(z1.size(0), device=z1.device)
return F.cross_entropy(sims, labels) # pull positive, push negatives
# ============== (B) BYOL / Non-contrastive loss ==============
def byol_loss(online_pred, target_proj):
"""No negatives. Predict the target view's embedding directly."""
online_pred = F.normalize(online_pred, dim=-1)
target_proj = F.normalize(target_proj, dim=-1)
return 2 - 2 * (online_pred * target_proj).sum(dim=-1).mean()
# ============== (C) MAE / Pixel reconstruction ==============
def mae_loss(pred_pixels, target_pixels, mask):
"""Reconstruct pixels of the masked patches."""
return ((pred_pixels - target_pixels) ** 2 * mask).sum() / mask.sum()
# ============== (D) JEPA / Embedding-space prediction ==============
def jepa_loss(predicted_target_embed, true_target_embed):
"""Predict the embedding of the masked region — not the pixels."""
return F.smooth_l1_loss(predicted_target_embed, true_target_embed)
# 차이를 한 줄씩 보면:
# (A) negatives을 멀리 밀어내는 사기 게임
# (B) negatives 없이 직접 target embedding을 따라가기
# (C) 픽셀까지 재현 — generative
# (D) target embedding만 맞추기 — non-generative
# JEPA는 (B)의 발상 + (C)의 마스킹 + 'embedding만'의 결합.
네 손실 함수의 차이가 핵심. SimCLR은 negative pair에 의존, BYOL은 EMA로 target을 따라가, MAE는 픽셀까지 재현, JEPA는 임베딩만 맞춤. 각 줄의 차이가 SSL 진화 5년의 흐름이고, JEPA는 그 누적의 결과다.
✅ 시니어가 보는 것
- Contrastive·Non-contrastive·Masked의 정확한 구분
- SimCLR·MoCo·BYOL·DINO·MAE 각각의 핵심 차이 즉답
- JEPA의 'BYOL+MAE의 비생성 합성' 위치 인지
- Augmentation 의존성·collapse 문제 같은 개념의 의미 이해
⚠️ 레드 플래그
- SimCLR과 MAE의 차이를 모름
- BYOL의 negative-free가 충격적 발견이라는 사실 모름
- MAE와 I-JEPA의 차이를 '비슷하다' 정도로만 이해
- Contrastive가 augmentation에 의존한다는 한계 모름
🎤 예상 인터뷰 질문
- SimCLR·BYOL·MAE의 핵심 차이를 각각 한 문장으로?
- BYOL이 negative pair 없이 학습 가능하다는 게 왜 충격이었나요?
- MAE와 I-JEPA의 본질적 차이는?
Key Takeaways
SSL = 라벨 없는 무한 데이터
라벨 없는 데이터에서 학습 신호를 자체 생성.
Contrastive (2020)
SimCLR·MoCo. Positive vs negative. Augmentation 의존.
Non-contrastive (2020-21)
BYOL·DINO. Negative 없이도 됨. EMA로 collapse 방지.
MAE (2021)
마스크된 패치의 픽셀 재구성. Generative.
I-JEPA의 발상
MAE를 비생성으로. 임베딩만 예측.
JEPA = 셋의 합성
BYOL의 두 인코더 + MAE의 마스킹 + 비생성.
Predictor 모듈
JEPA가 명시적으로 도입한 새 부품.
EMA target
Collapse 방지의 BYOL 트릭 그대로 계승.