The JEPA Architecture
JEPA 아키텍처의 정확한 정의
두 인코더 + Predictor + 잠재 변수 z. 에너지 함수 E(x,y,z) = D(sy, Pred(sx,z))로 정의되는 비생성 학습 아키텍처. EBM과 LVM의 결합이 수학적 토대.
Overview
1-3장에서 "왜 JEPA가 필요한가"의 큰 그림을 봤다. 이번 장은 정확한 수학 정의로 들어간다. JEPA = Joint Embedding Predictive Architecture. 단어 하나하나가 의미를 가진다.
- Joint Embedding (결합 임베딩): 두 개의 인코더가 각각 임베딩을 만든다
- Predictive (예측형): 한 임베딩으로부터 다른 임베딩을 예측
- Architecture (아키텍처): 구체적 모델이 아니라 "이런 모양의 모델들의 일반 틀"
이 장이 코스의 가장 기술적인 장이지만, 외우면 5-8장의 모든 디테일이 자기 자리를 찾는다.
- JEPA의 정확한 수학적 정의를 외운다
- 두 인코더와 Predictor의 역할을 그림으로 그릴 수 있다
- 잠재 변수 z가 정확히 무엇을 하고 왜 필요한지 안다
- Energy function이 무엇이고 왜 'energy'라 부르는지 안다
- JEPA가 EBM과 LVM의 결합임을 설명할 수 있다
Sections
4.1 한 그림으로 본 JEPA
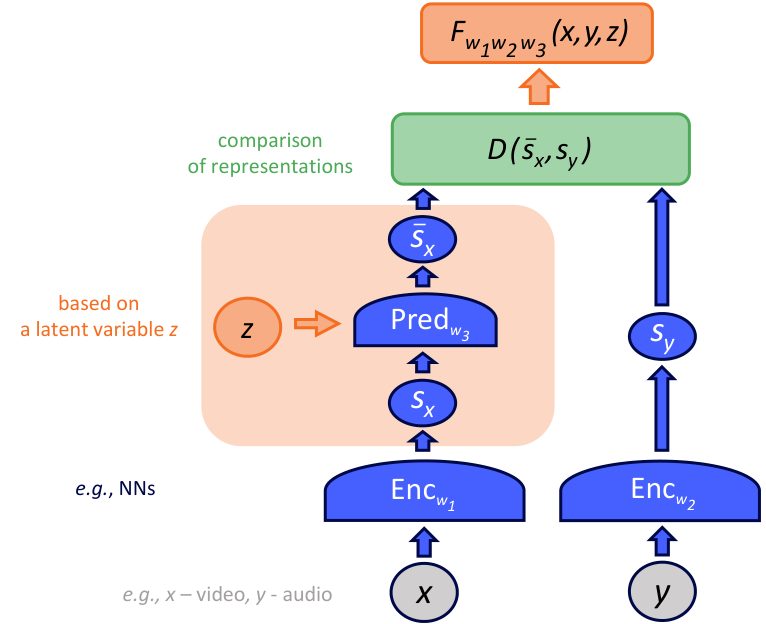
JEPA의 전체 흐름:
x (input 1) ──→ [Encoder_x] ──→ sx ──┐
↓
[Predictor(z)] ──→ ŝy (predicted)
↑
z (latent) ──────────────────────── ┘
↓
[Distance D]
↑
y (input 2) ──→ [Encoder_y] ──→ sy ──────────┘
입력: x와 y. 둘은 "관련된 두 데이터". 이미지에선 "한 이미지의 context block과 target block". 비디오에선 "한 비디오의 이전 시점과 이후 시점". 또는 "마스크되지 않은 부분과 마스크된 부분".
Encoder_x, Encoder_y: 각각 x와 y를 임베딩(고정 차원의 벡터)으로 변환. 두 인코더는 보통 같은 아키텍처지만 가중치가 다르다 (target encoder는 EMA로 천천히 업데이트).
Predictor: sx를 받아 sy를 추측한다. 단순히 sx → sy의 함수가 아니라 잠재 변수 z도 함께 받는다.
잠재 변수 z: "x로부터 y를 결정할 수 없는 모든 자유도"를 담는 변수. 예: x = 부엌 사진, y = 1초 뒤의 같은 부엌. 그 1초 사이에 일어날 수 있는 여러 가능성(누가 들어왔다, 컵이 움직였다) 중 어느 것인지를 z가 표현.
Distance D: predictor가 만든 ŝy와 진짜 sy의 거리. 보통 L2 또는 smooth L1.
에너지 함수: E(x, y, z) = D(sy, Pred(sx, z)). 작을수록 "x와 y가 잘 호환된다"는 의미.
출처: LeCun 2022 §4.4, 식 (10).
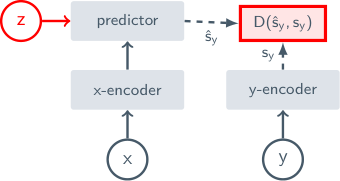
4.2 왜 두 개의 인코더인가
초보자가 자주 묻는 질문: "같은 인코더 하나 쓰면 안 되나? 왜 두 개?"
이유 1 — Collapse 방지. 한 인코더면 "모든 입력에 0벡터를 뱉으면 거리가 0이라 학습이 끝"의 trivial 해답이 가능. 두 인코더 + EMA target은 BYOL이 발견한 이 함정 회피 전략의 직접적 계승.
이유 2 — x와 y가 다른 종류일 수 있음. 예: x = 이미지, y = 텍스트(VLA-JEPA 식). 또는 x = 비디오, y = 액션 시퀀스. 다른 modality엔 다른 인코더가 자연스러움.
이유 3 — Target은 "안정된" 표현이어야 함. Predictor가 sy를 따라가는데 sy 자체도 학습 중이면 표적이 흔들림. EMA로 천천히 움직이는 target encoder가 안정된 표적 제공.
구현 디테일 (대부분의 JEPA에서 공통):
- Encoder_x(context encoder): 일반 backprop으로 학습
- Encoder_y(target encoder): Encoder_x의 EMA (예: 0.996 × old + 0.004 × new). 가중치 직접 학습 X
- target 쪽엔 gradient stop — predictor가 따라가야 할 표적이지 backprop의 대상이 아님
4.3 잠재 변수 z의 역할
z는 JEPA의 가장 미묘한 부품이다. 2장에서 LeCun의 두 번째 비판 — "LLM은 abstract latent variable이 없어 다중 해석·계획이 불가능" — 의 답이 바로 이 z.
z의 의미: "x만 보고선 결정할 수 없는, y의 모든 자유도".
구체적 예 1 (이미지): x = 이미지의 일부 patch. y = 같은 이미지의 가려진 patch. z = 가려진 patch의 모호한 정보. "이 자리에 컵이 있는지 잔이 있는지, 빨강인지 파랑인지"를 z가 담는다.
구체적 예 2 (비디오): x = 현재 프레임. y = 1초 뒤. z = 그 사이 일어난 사건. "누가 방에 들어왔다 / 안 들어왔다".
왜 중요한가: 1.
다중 해석 표현 가능: 같은 z를 바꿔가며 "이럴 수도 저럴 수도"의 여러 답을 표현 2.
계획에 활용: actor가 z(가설)들을 탐색해 "어떤 미래가 가장 좋은가"를 선택 3.
목표 설정: z를 "goal"로 사용 가능. "이런 결과(y)가 나오게 하는 z는 무엇인가"
현실: I-JEPA·V-JEPA의 첫 버전들은 z를 단순화하거나 생략하기도 한다. z의 풍부한 활용은 후속 연구의 과제. V-JEPA 2-AC에서 액션이 z 역할을 하는 식으로 발전.
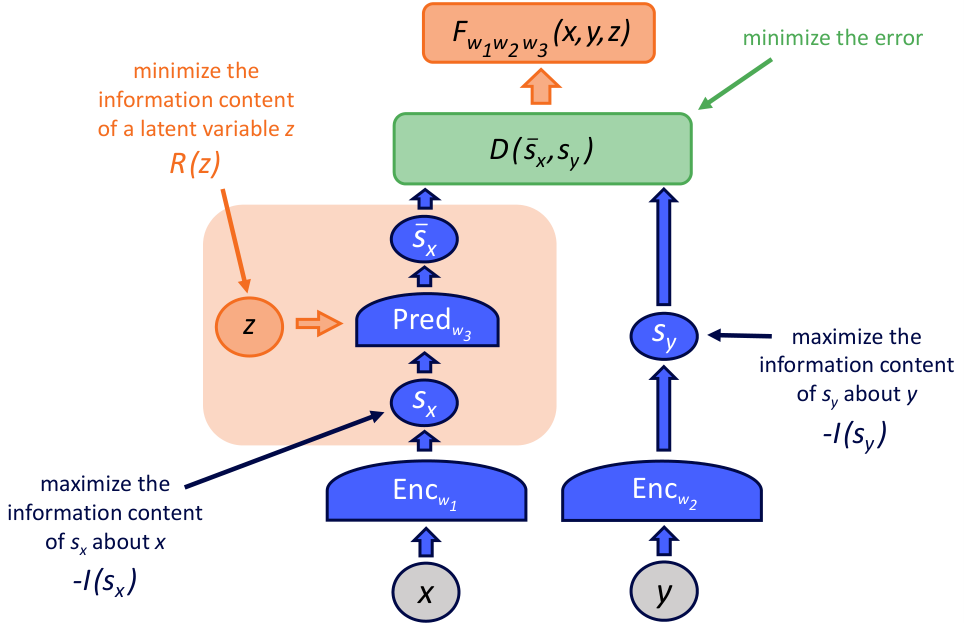
4.4 에너지 함수와 EBM
JEPA의 수학 토대는 Energy-Based Models(EBM).
EBM의 발상: 모든 가능한 (x, y) 짝마다 "에너지"라는 스칼라를 정의. 잘 어울리는 짝엔 낮은 에너지, 안 어울리는 짝엔 높은 에너지. 학습은 "training 데이터의 에너지를 낮추고, 다른 짝의 에너지를 높이는" 게임.
JEPA의 에너지: E(x, y, z) = D(sy, Pred(sx, z))
= 인코더가 만든 sy와 predictor가 추측한 ŝy의 거리.
왜 'energy'라는 이름? 물리에서 차용. 물체가 가장 안정적인 위치엔 에너지가 가장 낮음 — 마찬가지로 "가장 그럴듯한 (x, y) 짝"엔 가장 낮은 에너지.
Latent Variable Models (LVM)과의 결합: z를 "숨은 변수"로 다루는 게 LVM. JEPA는 EBM의 에너지 정의 + LVM의 z 도입을 합쳤다. 수학적으로는:
= "가장 좋은 z를 골랐을 때의 에너지". 또는 평균:
이 결합이 "표현 공간에서 비생성 예측을 정의하는 형식 언어"를 제공. 출처: Dawid & LeCun 2023, arXiv 2306.02572, Les Houches 2022 강의 노트.
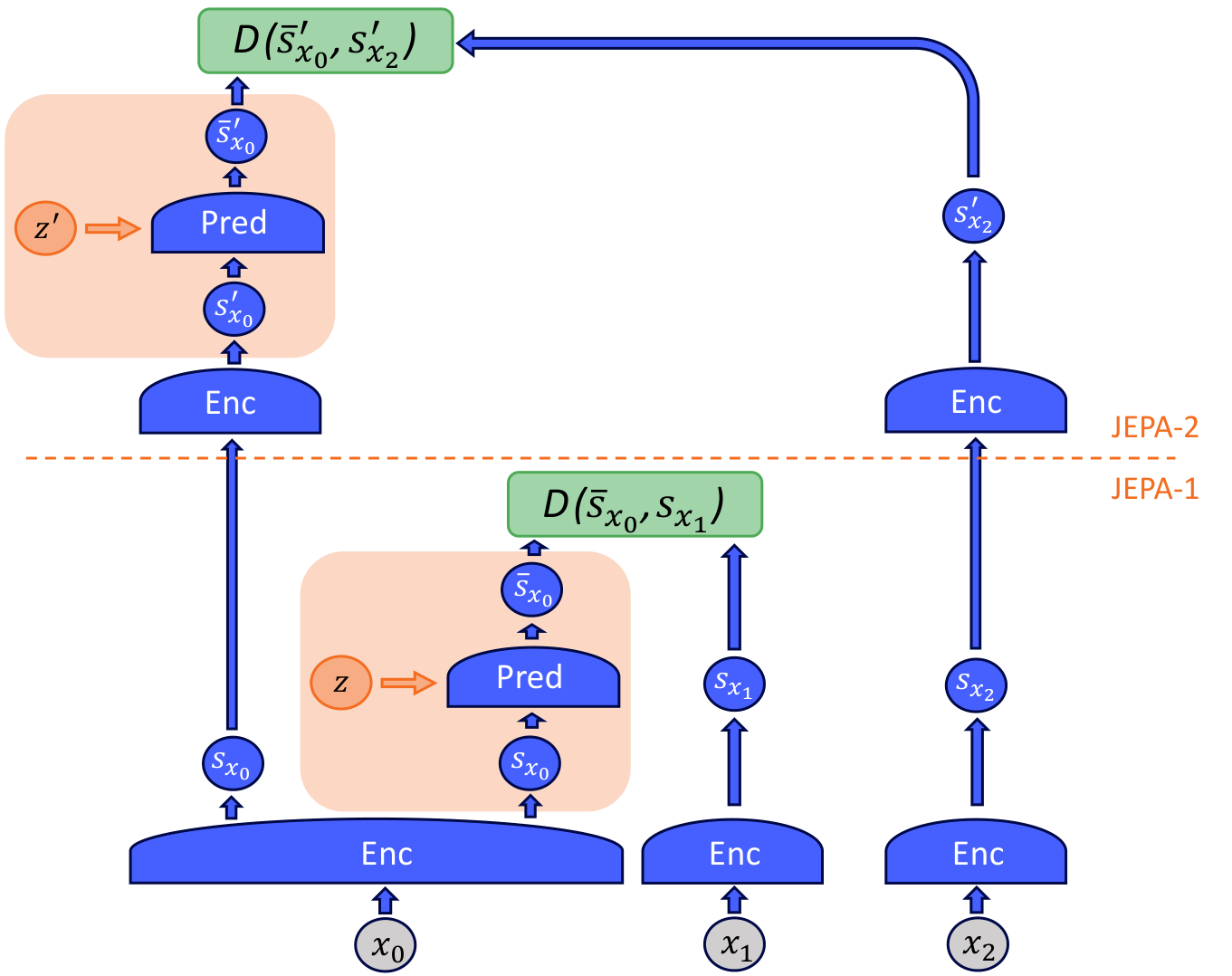
4.5 H-JEPA — 계층적 stacking
LeCun의 비전 문서에서 JEPA는 **"빌딩 블록"**이라고 표현된다. 즉 단일 JEPA로 끝이 아니라 여러 개를 쌓아야 진짜 자율 지능이 된다.
Hierarchical JEPA (H-JEPA): 여러 JEPA를 추상도 수준으로 쌓는다.
- 낮은 수준의 JEPA: 짧은 시간(0.1초)의 미세 동작(손 궤적)을 정확히 예측
- 중간 수준의 JEPA: 몇 초의 행동(컵을 들어 마시기)을 예측
- 높은 수준의 JEPA: 분·시간 단위 계획(저녁을 준비한다 → 재료 사기 → 요리)을 예측
왜 계층이 필요한가: 낮은 수준에서 장기 예측은 불가능 — 0.1초 단위로 시간이 길어질수록 가능성이 폭증. 그러나 "30분 뒤에 저녁 먹는다"는 추상 수준에선 예측 가능.
LeCun의 비유: 손가락 끝의 정확한 좌표는 1초도 못 예측. 그러나 "크레페를 굽는다"는 추상 행동은 10분도 예측 가능.
현실: 2026년 6월 기준 H-JEPA는 이론적 제안이고, 실제 구현·검증은 V-JEPA 2의 단일 JEPA 수준에서 막 시작. H-JEPA의 진짜 데모는 아직 미래.
출처: LeCun 2022 vision paper §6, Dawid & LeCun 2023 ("H-JEPA serves as the building block of LeCun's proposal").
한국어를 영어로 번역하는 시스템을 만든다고 치자. 단순한 발상은 "한국어 문장 x → 영어 문장 y". 그러나 JEPA식 접근은 다르다.
통역사 A(Encoder_x)와 통역사 B(Encoder_y)가 따로 있다. A는 한국어 문장 x를 받아 "의미 임베딩" sx를 만든다. B는 영어 문장 y를 받아 같은 차원의 "의미 임베딩" sy를 만든다.
그 사이에 예측가(Predictor)가 있다. 예측가는 sx를 받아 "이 한국어가 영어로 어떤 의미가 될까"를 추측해 ŝy를 만든다. 그리고 "같은 의미를 가진 영어 문장에 대해 통역사 B가 만든 sy"와 비교.
잠재 변수 z: 한국어 "안녕"이 영어로 "hi"인지 "hello"인지 "hey"인지의 선택. z를 바꿔가며 여러 답이 가능.
에너지가 낮을수록 통역사 A·예측가·통역사 B가 일관된다는 의미. 학습은 그 에너지를 낮추는 게임. 그리고 이 셋이 픽셀이나 정확한 글자 단위로 비교하지 않는다 — 의미 임베딩 공간에서만 비교. 그래서 "안녕"을 "hi/hello/hey" 중 어느 글자로 정확히 쓰느냐의 불필요한 디테일은 학습에 안 들어옴. 이게 JEPA의 정신.
JEPA의 forward pass와 손실 함수를 PyTorch로. 두 인코더, predictor, EMA target update까지 포함. 실제 I-JEPA·V-JEPA 구현의 가장 단순화한 형태.
import torch
import torch.nn as nn
import torch.nn.functional as F
from copy import deepcopy
class MinimalJEPA(nn.Module):
def __init__(self, embed_dim=128, z_dim=16, momentum=0.996):
super().__init__()
# Encoder_x — trained with backprop
self.context_encoder = nn.Sequential(
nn.Linear(256, embed_dim), nn.GELU(),
nn.Linear(embed_dim, embed_dim),
)
# Encoder_y — EMA copy, no gradient
self.target_encoder = deepcopy(self.context_encoder)
for p in self.target_encoder.parameters():
p.requires_grad = False
# Predictor — sx + z → ŝy
self.predictor = nn.Sequential(
nn.Linear(embed_dim + z_dim, embed_dim), nn.GELU(),
nn.Linear(embed_dim, embed_dim),
)
self.momentum = momentum
@torch.no_grad()
def update_target(self):
"""EMA update: target ← m·target + (1-m)·context."""
for p_ctx, p_tgt in zip(
self.context_encoder.parameters(),
self.target_encoder.parameters(),
):
p_tgt.data.mul_(self.momentum).add_(
p_ctx.data, alpha=1 - self.momentum
)
def forward(self, x, y, z):
sx = self.context_encoder(x) # learnable
with torch.no_grad():
sy = self.target_encoder(y) # stop-grad target
sy_pred = self.predictor(torch.cat([sx, z], dim=-1))
# Energy = distance in embedding space
energy = F.smooth_l1_loss(sy_pred, sy)
return energy
# Training step
model = MinimalJEPA()
opt = torch.optim.Adam(
[p for p in model.parameters() if p.requires_grad], lr=1e-4
)
for step in range(100):
x = torch.randn(32, 256) # context (e.g., visible patches)
y = torch.randn(32, 256) # target (e.g., masked patches)
z = torch.randn(32, 16) # latent — sampled or learned
energy = model(x, y, z)
opt.zero_grad(); energy.backward(); opt.step()
model.update_target() # EMA
if step % 20 == 0:
print(f'step {step}: energy={energy.item():.4f}')
이 50줄이 JEPA의 정수다. context_encoder만 backprop. target_encoder는 EMA로 천천히 따라감. predictor가 sx와 z로 ŝy 추측. 에너지는 ŝy와 sy의 임베딩 공간 거리. 실제 I-JEPA·V-JEPA는 인코더가 ViT(Vision Transformer)이고 입력이 패치 시퀀스라는 차이만 있다. 핵심 학습 신호는 정확히 이 한 줄: F.smooth_l1_loss(sy_pred, sy).
✅ 시니어가 보는 것
- 에너지 함수 E(x,y,z) = D(sy, Pred(sx,z))를 즉답
- 두 인코더가 왜 필요한지(collapse + 표적 안정) 설명 가능
- z의 역할(다중 해석·계획)을 LeCun의 §8.3.1 두 번째 비판과 연결
- EBM + LVM의 결합이라는 수학 토대를 안다
⚠️ 레드 플래그
- JEPA의 손실 함수를 contrastive로 오해
- Predictor가 단순 sx→sy 함수라고 생각 (z 없는 채로)
- EMA target update의 의미 모름
- Energy를 단순 'loss'와 동일시
🎤 예상 인터뷰 질문
- JEPA의 에너지 함수를 칠판에 적어보세요
- 왜 두 인코더가 필요한가요? 한 인코더로는 안 되는 이유는?
- 잠재 변수 z의 정확한 역할은? z 없는 JEPA는 무엇이 부족한가요?
Key Takeaways
Joint Embedding Predictive Architecture
두 인코더 + Predictor + z.
Energy function
E(x,y,z) = D(sy, Pred(sx,z)).
두 인코더
Collapse 방지 + 안정된 표적 + 다른 modality 가능.
EMA target
Target은 backprop X. EMA로 천천히 업데이트.
Latent z
다중 해석·목표 탐색의 자유도.
EBM + LVM 토대
Energy-Based + Latent Variable의 결합.
Non-generative
픽셀 X, 임베딩만. Unpredictable detail 무시 가능.
H-JEPA = 빌딩 블록
여러 JEPA를 추상도로 쌓는 것이 LeCun의 종착점.