I-JEPA — Images First (2023)
I-JEPA — 이미지에 적용한 첫 JEPA
Assran 등이 2023년 1월에 발표한 첫 JEPA 구현. 이미지의 context block에서 여러 target block의 표현을 예측. Hand-crafted augmentation에 의존하지 않는 게 핵심 차별점. CVPR 2023 발표.
Overview
2023년 1월 19일. arXiv 2301.08243. 제목 "Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture". Assran(1저자), Duval, Misra, Bojanowski, Vincent, Rabbat, LeCun, Ballas. CVPR 2023 발표.
이 논문이 JEPA 비전의 첫 실전 구현이다. LeCun이 2022년에 "이런 아키텍처가 있어야 한다"고 그린 청사진을 처음으로 코드로 옮긴 결과. 이번 장은 I-JEPA의 정확한 설계와 결과를 본다.
- I-JEPA의 정확한 논문 정보(저자·시기·발표 컨퍼런스)를 외운다
- context block과 target block의 정확한 마스킹 전략을 안다
- 왜 augmentation에 의존하지 않는 게 중요한 차별점인지 이해한다
- ViT(Vision Transformer)와 어떻게 결합되는지 설명할 수 있다
- I-JEPA가 MAE 등 generative SSL과 어떻게 다른지 비교 가능
Sections
5.1 논문의 기본 정보와 위치
기본 정보 외우기:
- 제목: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
- 저자: Mahmoud Assran(1저자), Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas (Meta AI / FAIR)
- arXiv: 2301.08243, v1 2023-01-19
- 발표: CVPR 2023
- 공식 블로그: https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/
이 논문이 학계에서 중요한 이유:
- LeCun 비전의 첫 실증. "이론적 아이디어"에서 "이미지 ImageNet linear probing이 SOTA 근접"의 실험까지.
- CVPR 2023 발표. 비전 학계의 최고 컨퍼런스에서 받아들여짐.
- Augmentation-free가 강조됨. 비전 SSL의 한 갈래 문제(augmentation 의존)를 우회.
- V-JEPA, V-JEPA 2의 모태. 이후 모든 JEPA가 I-JEPA의 디자인 패턴을 계승.
출처: arXiv 2301.08243, Meta AI 블로그 (검증된 사실).
5.2 핵심 발상 — Block masking으로 풀어쓰기
I-JEPA가 한 일을 한 문장으로: "하나의 이미지에서 큰 context block 하나를 인코딩하고, 그 인코딩으로부터 같은 이미지의 여러 target block의 표현을 예측한다."
각 부분을 풀면:
Context block: 이미지의 큰 영역(보통 85-100% 커버 후 target과 겹치는 부분 제거). "보이는 부분".
Target block: 같은 이미지의 다른 영역. 여러 개(보통 4개). 각각 이미지의 15-20% 크기. "가려진 부분".
예측의 방향: context의 임베딩 sx → target의 임베딩 sy. 픽셀이 아니라 임베딩.
Loss: target encoder가 만든 진짜 sy와 predictor가 만든 ŝy의 L2 거리. EMA target encoder는 gradient stop.
왜 multi-target인가? 한 target만 예측하면 "이 위치의 평균 임베딩" 같은 trivial 해답이 가능. 여러 target을 동시에 예측해야 의미 있는 표현이 강제됨.
왜 target이 15-20%인가? 너무 작으면(예: 5%) 주변 context로 거의 맞출 수 있어 "진짜 학습"이 안 됨. 너무 크면(예: 50%) context가 부족해 너무 어려움. 15-20%가 "맞추기 어렵지만 가능한" sweet spot.
출처: arXiv 2301.08243 §3, Meta AI 블로그.
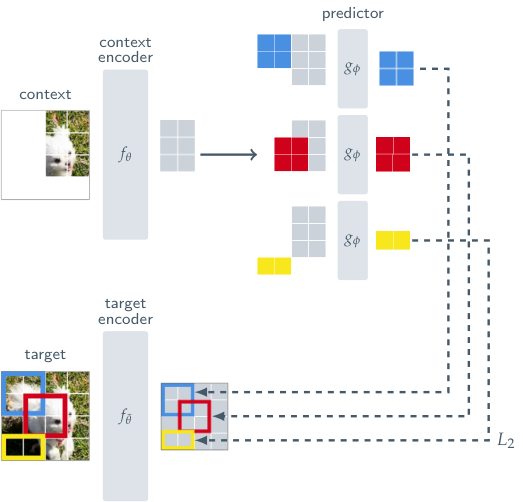

5.3 ViT 위에 올린다 — 구현 디테일
I-JEPA의 인코더와 predictor는 모두 ViT (Vision Transformer) 기반.
ViT 빠른 소개: 이미지를 작은 패치(예: 16×16 픽셀)로 자르고, 각 패치를 토큰으로 보고 Transformer에 입력. 텍스트의 word token을 이미지 patch로 바꿨다고 생각하면 됨.
I-JEPA의 구현:
- Context encoder: ViT-B/16 또는 ViT-L/16 (224×224 입력, 14×14 = 196 패치)
- Target encoder: 같은 ViT의 EMA copy
- Predictor: 작은 ViT (보통 6 layers, 384 dim). context의 token + 학습 가능한 "mask token"을 받아 target token의 임베딩을 예측
마스킹 흐름:
- 이미지를 14×14 패치로 자름
- Target block 4개를 샘플 — 각각 직사각형 영역, 15-20% 크기
- Context block 1개를 샘플 — 큰 영역, 그 다음 target과 겹치는 패치 제거
- Context encoder에 context의 패치들만 입력 → sx
- Target encoder에 전체 이미지 입력 후 target block의 패치들만 추출 → sy_true
- Predictor에 sx와 target 위치 정보(positional embedding) 입력 → sy_pred
- L = ||sy_pred - sy_true||²
전체 학습은 ImageNet-1K (1.28M 이미지)에서. 보통 600 epoch.
주의: "linear probing"이란 backbone을 얼린(frozen) 채로 마지막에 작은 분류기 하나만 학습해서 성능을 평가하는 표준 방식. SSL의 표현 품질을 객관적으로 측정.


5.4 결과 — 무엇이 잘 됐고 안 됐나
I-JEPA의 핵심 결과(arXiv 논문에서 verified):
잘 된 것:
- ImageNet linear probing 76%+ (ViT-H/14 + Multi-block masking)
- Hand-crafted augmentation 없음 — DINO 등 contrastive보다 훨씬 단순
- 학습이 안정적이고 빠름 (MAE보다 적은 epoch에 도달)
- Low-shot 분류, semi-supervised 분류에서 강한 transfer
한계:
- 가장 강한 contrastive(DINOv2 등) 대비 linear probing 점수는 살짝 낮음
- ImageNet linear probing이라는 단일 메트릭으로만 "좋다/나쁘다"를 평가하기엔 부족
- 이미지 한 장 내의 spatial reasoning 위주 — 시간·동작 다루지 못함 (그래서 V-JEPA가 필요)
연구계의 반응:
- 비교적 호의적. "새 SSL 패러다임을 제시"의 가치 인정
- 그러나 일부 비판도 — "단순히 MAE에서 픽셀을 임베딩으로 바꾼 것 아닌가"
- DINOv2(2023-04)가 비슷한 시기에 더 강한 결과를 보이며 contrastive 쪽도 발전
결국 I-JEPA의 진짜 가치는 단일 벤치마크 점수가 아니라 "JEPA 패러다임의 실증". 이게 가능했기에 V-JEPA, V-JEPA 2가 만들어질 수 있었다.
주의 — 본 코스의 deep research에서 "I-JEPA가 generative 대비 1.5-6x sample efficiency"의 주장은 검증 실패(1-2 vote로 기각)되어 본 코스에서 사용하지 않는다.
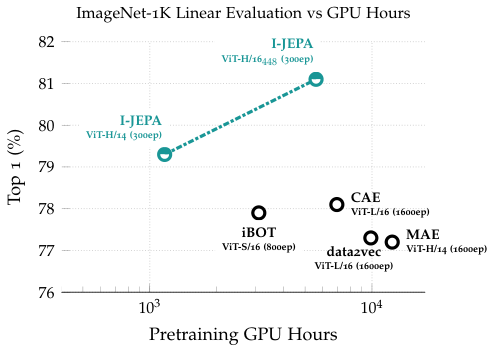
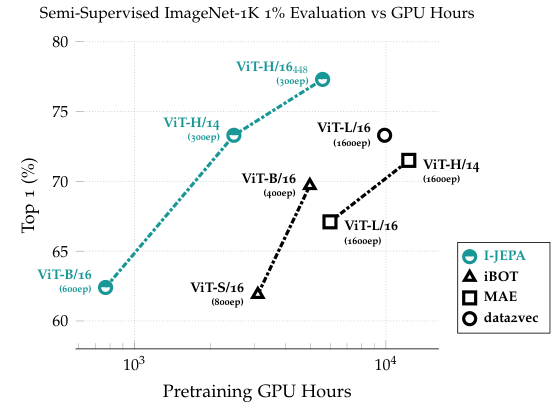
5.5 I-JEPA가 남긴 패턴들
I-JEPA는 단일 모델 이상의 의미가 있다. 이후 JEPA들이 그대로 계승한 디자인 패턴들을 정착시켰다.
패턴 1 — Block-level masking: 픽셀이나 패치 단위 random masking이 아니라 "큰 영역(block)"을 가리는 방식. 의미 있는 spatial 구조를 학습 신호로.
패턴 2 — Multi-target prediction: 한 context에서 여러 target. 단일 trivial 해답 방지.
패턴 3 — EMA target encoder: BYOL 패턴 계승. backprop 없는 target.
패턴 4 — ViT 기반: 이미지를 패치 시퀀스로 다루는 ViT가 마스킹·예측에 자연스럽게 맞음. 모든 후속 JEPA가 ViT 기반.
패턴 5 — Augmentation-free: hand-crafted augmentation의 가정을 줄임. 비디오·로봇 도메인으로의 확장이 쉬워짐.
이 다섯 패턴이 V-JEPA(6장), V-JEPA 2(7장)에서 시간축으로 확장될 때 그대로 계승된다. 자세한 디테일은 다음 두 장에서.
일간신문 한 페이지를 펼친다. 그 중 큰 영역(70%) — 1면 톱기사와 두 번째 기사 — 만 보고, **가려진 부분(15-20%)**이 어떤 "의미"일지 추측한다. 정확한 단어(픽셀)는 못 맞춰도 좋다. "이 자리엔 광고가 있을 것 같다", "여기엔 날씨 정보가 있을 것 같다" 정도의 추상 수준만 맞으면 OK.
이게 I-JEPA의 발상이다. 보이는 부분(context block)에서 가려진 부분(target block)의 의미 표현을 예측. 픽셀까지 맞출 필요 없음.
MAE는 같은 신문을 가지고 "정확한 활자를 픽셀 단위로 재구성하라"고 한다. 어렵고 무의미한 디테일에 학습 신호가 낭비. I-JEPA는 "의미만 맞춰라". 광고인지 기사인지, 정치 기사인지 스포츠 기사인지 정도면 충분. 불필요한 디테일은 처음부터 무시. 이게 가능하니까 학습이 더 빠르고, 표현이 더 의미 있게 정렬된다.
I-JEPA의 block masking + multi-target sampling을 직접 구현. 실제 공식 구현은 facebookresearch/ijepa GitHub에 있다.
import torch
import random
def sample_block_mask(num_patches_h=14, num_patches_w=14,
scale=(0.15, 0.20), aspect=(0.75, 1.5)):
"""Sample one rectangular block mask covering 15-20% of patches."""
total = num_patches_h * num_patches_w
s = random.uniform(*scale)
target_size = int(total * s)
ar = random.uniform(*aspect)
h = int(round((target_size * ar) ** 0.5))
w = int(round((target_size / ar) ** 0.5))
h = min(h, num_patches_h); w = min(w, num_patches_w)
top = random.randint(0, num_patches_h - h)
left = random.randint(0, num_patches_w - w)
mask = torch.zeros(num_patches_h, num_patches_w, dtype=torch.bool)
mask[top:top+h, left:left+w] = True
return mask
def ijepa_sample_masks(num_targets=4, num_patches_h=14, num_patches_w=14):
"""Sample 4 target blocks and 1 context block (context excludes target patches)."""
# 1) Sample target blocks (15-20% each)
target_masks = [
sample_block_mask(num_patches_h, num_patches_w)
for _ in range(num_targets)
]
# 2) Sample context block (85-100% coverage)
context = sample_block_mask(
num_patches_h, num_patches_w,
scale=(0.85, 1.0), aspect=(1.0, 1.0)
)
# 3) Remove target patches from context to prevent leakage
for tm in target_masks:
context = context & ~tm
return context, target_masks
# Usage in training step (sketch)
context_mask, target_masks = ijepa_sample_masks()
context_patches = patches[context_mask] # what encoder sees
target_patches = [patches[tm] for tm in target_masks] # what to predict
sx = context_encoder(context_patches) # context embedding
predictions = [predictor(sx, tm) for tm in target_masks] # predict each target's embedding
with torch.no_grad():
targets = [target_encoder(patches)[tm] for tm in target_masks] # ground truth
loss = sum(torch.nn.functional.smooth_l1_loss(p, t)
for p, t in zip(predictions, targets))
print(f'Training loss = {loss.item():.4f}')
마스킹의 두 단계 — multi-target + context, 그리고 context에서 target 패치를 빼는 디테일 — 이 I-JEPA의 핵심. 4개 target 각각이 15-20% 크기, context가 85-100%에서 시작해 target 부분을 잘라낸다. 이 마스킹이 "맞추기 어렵지만 가능한" 균형을 만들어 의미 있는 표현 학습을 강제한다.
✅ 시니어가 보는 것
- arXiv 번호·1저자·CVPR 2023 발표 즉답
- Context-target block의 정확한 비율(15-20%)과 multi-target 이유
- EMA target encoder + augmentation-free의 디자인 의의 이해
- MAE와 I-JEPA의 본질적 차이(픽셀 vs 임베딩) 설명
⚠️ 레드 플래그
- I-JEPA를 MAE의 변종 정도로 이해
- Multi-target의 이유(collapse 방지) 모름
- ViT 기반 아키텍처 모름
- ImageNet linear probing이 SSL 표준 평가 방식임을 모름
🎤 예상 인터뷰 질문
- I-JEPA의 마스킹 전략을 구체적으로 설명해 주세요
- 왜 target block을 4개 만들고, 왜 15-20% 크기인가요?
- I-JEPA와 MAE의 본질적 차이는?
Key Takeaways
I-JEPA 기본정보
arXiv 2301.08243, 2023-01, Assran 1저자, CVPR 2023.
Context + multi-target
1개 context(85-100%) + 4개 target(15-20% 각각).
예측 대상
Target 영역의 픽셀이 아니라 임베딩.
Augmentation-free
Hand-crafted augmentation 의존 없음 — 핵심 차별점.
ViT 기반
Context·target·predictor 모두 ViT.
EMA target
BYOL 패턴 계승. Backprop X.
ImageNet linear probing
SSL 표준 평가. 76%+ 달성.
후속의 모태
V-JEPA·V-JEPA 2가 동일 패턴 시간축으로 확장.