V-JEPA — Adding Time (2024)
V-JEPA — 시간축으로 확장 (2024)
2024년 2월 15일 Meta가 공개. Bardes 등의 'Revisiting Feature Prediction'. I-JEPA의 마스킹 발상을 비디오의 시공간 영역으로 확장. ViT-H/16으로 Kinetics-400 81.9%, SSv2 72.2%, ImageNet 77.9% (frozen evaluation).
Overview
I-JEPA(5장)는 이미지 한 장 안의 공간만 다뤘다. World Model은 시간을 다뤄야 한다. 미래를 예측해야 하니까. 그 자연스러운 다음 단계가 V-JEPA다. 2024년 2월 15일 arXiv 2404.08471로 공개. Bardes 등 8명의 저자.
이 장은 V-JEPA가 어떻게 I-JEPA의 발상을 비디오로 확장했고, 어떤 벤치마크에서 어떤 점수를 받았는지를 본다. 검증된 사실만 다룬다.
- V-JEPA의 정확한 논문 정보와 발표 시기를 외운다
- I-JEPA의 마스킹이 어떻게 시공간으로 확장되는지 안다
- 'Feature prediction only'가 무엇이고 왜 강조되는지 이해한다
- Kinetics-400·Something-Something-v2 벤치마크의 의미를 안다
- 왜 V-JEPA가 World Model의 첫 진짜 후보인지 본다
Sections
6.1 논문 기본 정보
- 제목: Revisiting Feature Prediction for Learning Visual Representations from Video
- 저자: Adrien Bardes(1저자), Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, Nicolas Ballas (Meta FAIR + INRIA)
- arXiv: 2404.08471, v1 2024-02-15
- 공식 블로그: https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/
주의 — "V-JEPA를 LeCun이 이끌었다"는 Meta 공식 마케팅 프레이밍이고, 실제 1저자는 Adrien Bardes다. 학술적 인용 시엔 Bardes et al., 2024 형식이 정확.
발표의 메시지(저자가 초록에 직접 적은): "We revisit feature prediction as a stand-alone objective for self-supervised learning from video" — "feature prediction을 비디오 SSL의 독립 objective로 다시 본다". I-JEPA의 발상을 비디오에 적용한다는 선언.
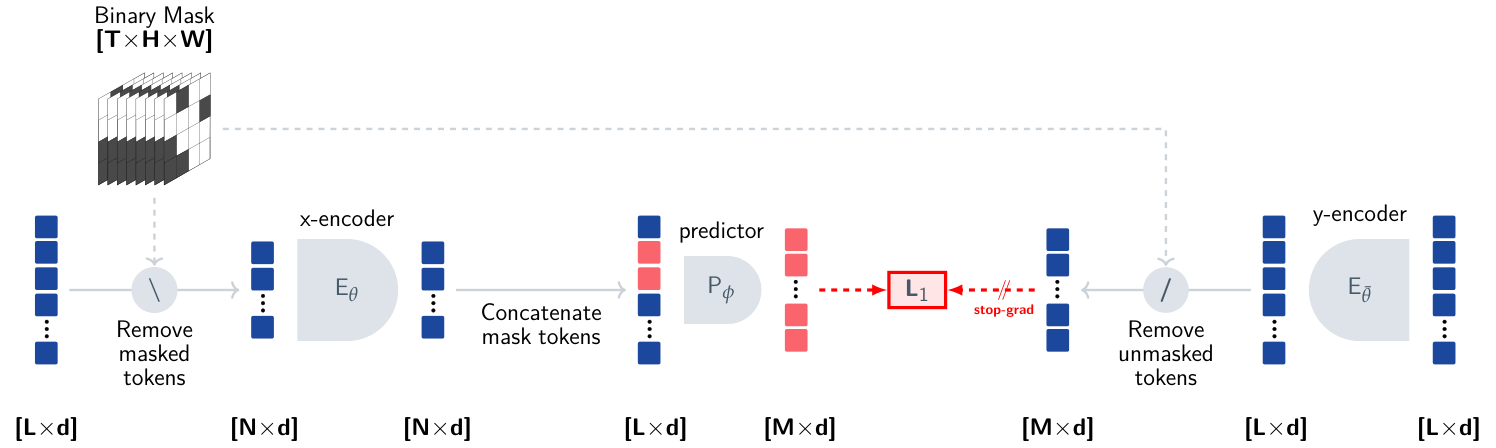
6.2 시공간 마스킹 — I-JEPA의 자연스러운 확장
I-JEPA가 "이미지의 spatial block을 가린다"였다면 V-JEPA는 "비디오의 spatio-temporal block을 가린다".
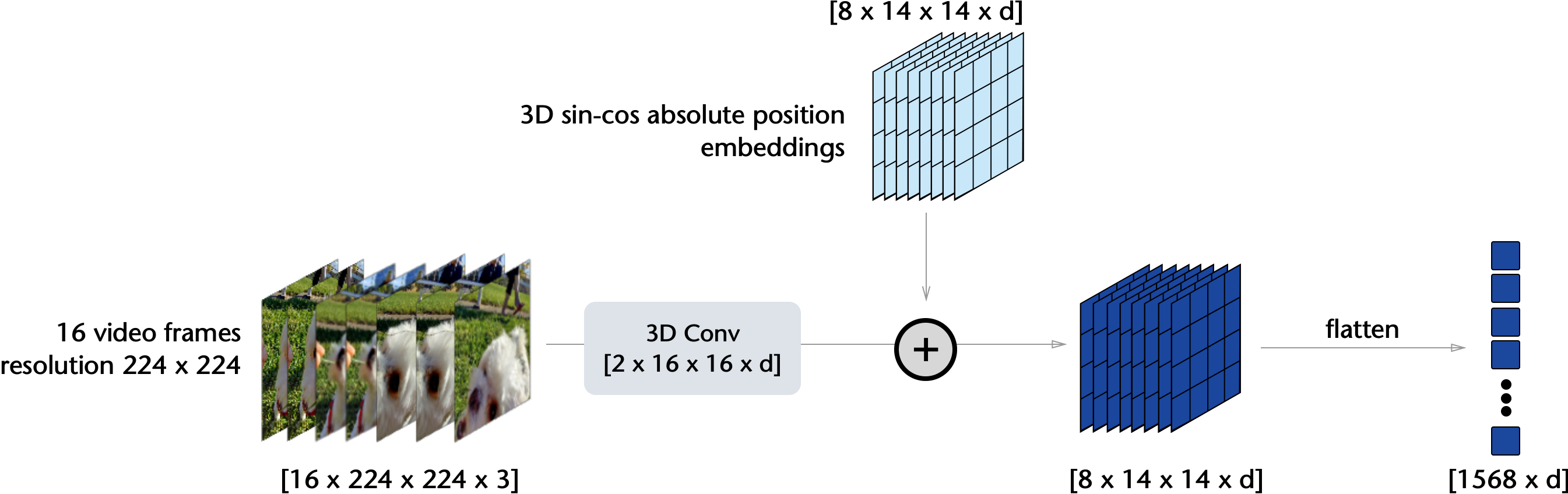
비디오는 (T, H, W) 3차원. 16프레임 × 224×224 정도가 일반적 입력 크기. ViT가 이를 작은 patch tube로 자른다 — 예: 2 프레임 × 16×16 픽셀 = 한 tubelet. 이 tubelet들이 토큰.
마스킹 전략:
- 시간 + 공간에서 "큰 블록" 마스킹
- 한 블록이 보통 여러 프레임에 걸친 공간 영역을 가림
- I-JEPA처럼 multi-target (여러 block을 동시에 예측)
- Context는 가려지지 않은 tubelet들
예측 대상: 가려진 tubelet의 임베딩. 픽셀이 아니라 임베딩. JEPA의 정신 그대로.
왜 시공간 블록인가? 비디오의 본질은 "한 객체가 시간에 걸쳐 어떻게 움직이는가". 한 프레임 안의 한 픽셀만 가리면 다른 프레임의 같은 픽셀로 trivial하게 맞춤. 여러 프레임에 걸친 큰 영역을 가려야 "이 객체가 어떻게 움직였는지"를 학습해야 한다.
6.3 'Feature prediction only' — 강한 주장
V-JEPA 논문의 초록에는 강한 주장이 있다 (verified 인용):
"trained solely using a feature prediction objective, without the use of pretrained image encoders, text, negative examples, reconstruction, or other sources of supervision." (오직 feature prediction objective만으로 학습. 사전학습된 image encoder, 텍스트, negative example, reconstruction, 그 외 어떤 감독도 사용 안 함.)
이 한 줄이 V-JEPA의 자기 차별점.
무엇과 비교하나:
- Pretrained image encoder 없음: VideoMAE 등은 종종 ImageNet pretrained ViT로 시작. V-JEPA는 처음부터.
- 텍스트 없음: CLIP 류는 텍스트-이미지 짝으로 학습. V-JEPA는 텍스트 0%.
- Negative example 없음: Contrastive SSL의 핵심. V-JEPA는 BYOL/DINO처럼 non-contrastive.
- Reconstruction 없음: MAE/VideoMAE는 픽셀 재구성. V-JEPA는 임베딩만.
결과: 이 'feature prediction'만으로 SOTA에 근접한 성능을 얻었다는 게 논문의 핵심 결과.
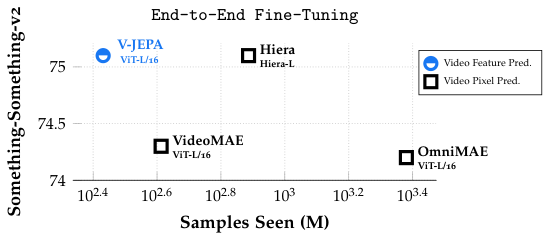
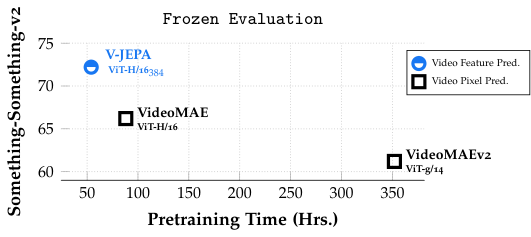
6.4 벤치마크 결과 — 정확한 숫자
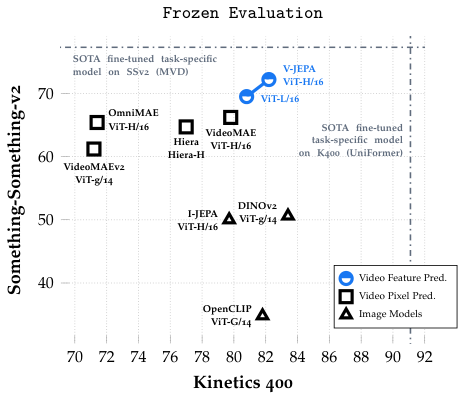
V-JEPA ViT-H/16 (frozen backbone + attentive probe)의 결과 (검증된 사실):
| 벤치마크 | V-JEPA ViT-H/16 | 의미 |
|---|---|---|
| Kinetics-400 (top-1) | 81.9% | 일반 동작 분류 (400 클래스) |
| Something-Something-v2 (top-1) | 72.2% | 미세 동작 이해 (174 클래스, "손으로 X 들어올리기" 같은) |
| ImageNet1K (top-1) | 77.9% | 이미지 분류로의 전이 |
'Frozen backbone + attentive probe'의 의미: backbone(ViT-H/16)의 가중치를 동결하고, 뒤에 작은 attention pooling + linear classifier만 학습해서 평가. SSL 표현의 "순수한 품질"을 측정.
왜 SSv2(Something-Something-v2)가 중요한가: 미세 동작 이해의 표준 벤치마크. "왼손으로 컵을 오른쪽으로 옮기기" vs "왼손으로 컵을 들어 다시 내려놓기" 같은 세밀한 차이를 구분. 시간적 추론을 강제하는 벤치마크.
Kinetics-400 81.9%의 의미: 시청각 행동 분류에서 SSL 모델로는 매우 강한 점수. supervised 학습 SOTA(~85%)에 근접하면서 라벨을 전혀 안 쓴 모델로 도달.
출처: arXiv 2404.08471 초록 verbatim, Meta AI 블로그.
주의 — deep research에서 "V-JEPA가 generative보다 1.5-6x sample efficiency"의 주장은 검증 실패(1-2 vote로 기각). 본 코스에서 그 주장은 사용 안 함.
6.5 V-JEPA가 World Model의 '첫 후보'인 이유
I-JEPA(이미지)에서 V-JEPA(비디오)로 가는 게 단순한 "한 차원 추가"가 아니다. World Model의 본질적 자격을 갖췄다는 의미.
World Model이 되려면 필요한 것: 1.
상태(state) 표현: 현재 세계가 어떤지를 임베딩으로 — V-JEPA가 시공간 영역의 임베딩으로 제공 2.
미래 예측: 보이지 않는 부분(미래·가려진 시점)의 표현을 예측 — 시공간 masking이 정확히 이걸 학습 3.
추상 수준의 시뮬레이션: 픽셀 단위가 아닌 임베딩 단위 — JEPA의 정신 그대로
V-JEPA는 이 셋을 모두 만족하는 첫 모델. 다만 V-JEPA 자체는 "행동(action)"이 빠짐 — 어떤 행동을 했을 때 어떤 미래가 되는지가 명시적으로 들어가지 않음. 단순히 "비디오의 가려진 부분 예측"만 학습.
**그래서 V-JEPA 2 (7장)**가 "action-conditioned" 변형을 추가하며 World Model의 자격을 더 완전히 갖춘다. V-JEPA는 그 길로 가는 중간 단계.
영화 한 편을 보다가 갑자기 5초 동안 화면이 검게 나간다고 치자. 그러나 사라진 5초 직전과 직후는 정상이다. 이때 머릿속에서 자동으로 "그 5초 동안 무슨 일이 있었을까"를 채운다.
정확한 픽셀까지 그릴 필요는 없다. "주인공이 방으로 들어와서 컵을 들어 마셨을 거다" 정도의 추상 수준이면 다음 장면이 이해된다. 사람 뇌가 비디오를 보는 방식이다.
V-JEPA가 이걸 학습한다. 비디오의 시공간 영역 일부를 가리고, 가려진 부분의 의미 임베딩을 예측. 픽셀까진 안 만든다. "주인공이 컵을 마셨다"는 행동 수준의 표현만 맞으면 OK.
이 능력이 World Model의 본질이다. 정확한 픽셀 시뮬레이션이 아니라 "의미 수준"의 시뮬레이션. V-JEPA는 그걸 처음으로 데이터에서 자동 학습한 모델.
V-JEPA의 spatio-temporal masking + tubelet 임베딩 예측을 단순화해 구현. 실제 facebookresearch/jepa의 마스킹 함수를 단순화한 형태.
import torch
import random
def sample_spatio_temporal_mask(
num_frames=16, num_patches_h=14, num_patches_w=14,
temporal_size=8, spatial_scale=0.25,
):
"""Mask a 'tube' covering several frames and a spatial region."""
# Temporal span
t_start = random.randint(0, num_frames - temporal_size)
t_end = t_start + temporal_size
# Spatial block size
total_spatial = num_patches_h * num_patches_w
target_spatial = int(total_spatial * spatial_scale)
h = w = int(target_spatial ** 0.5)
top = random.randint(0, num_patches_h - h)
left = random.randint(0, num_patches_w - w)
mask = torch.zeros(num_frames, num_patches_h, num_patches_w, dtype=torch.bool)
mask[t_start:t_end, top:top+h, left:left+w] = True
return mask
def vjepa_step(video, context_encoder, target_encoder, predictor):
"""One V-JEPA forward pass."""
# video: (B, T, H, W, 3) — but tokenized into (B, N_tokens, D) by ViT
target_mask = sample_spatio_temporal_mask() # which tokens to predict
context_mask = ~target_mask # everything else is context
# 1) Tokenize
tokens = video_to_tokens(video) # (B, N, D)
flat_context = context_mask.flatten()
flat_target = target_mask.flatten()
# 2) Context encoder — sees only unmasked tokens
sx = context_encoder(tokens[:, flat_context])
# 3) Target encoder — sees all tokens, output for masked positions only
with torch.no_grad():
sy_full = target_encoder(tokens)
sy = sy_full[:, flat_target]
# 4) Predictor: from sx + target positional info → ŝy
target_pos_embed = positional_embedding[flat_target]
sy_pred = predictor(sx, target_pos_embed)
# 5) Loss: smooth L1 in embedding space
loss = torch.nn.functional.smooth_l1_loss(sy_pred, sy)
return loss
# 학습 흐름은 I-JEPA와 동일하지만 mask가 시공간 차원으로 확장됨
I-JEPA 코드에서 mask가 2D였다면 V-JEPA는 3D (T, H, W). 한 tube가 여러 프레임에 걸친 공간 영역을 가린다. 이 마스킹이 모델이 시간적 동작을 학습하도록 강제. 나머지(인코더·predictor·EMA·L2 손실)는 I-JEPA와 동일한 구조.
✅ 시니어가 보는 것
- K400 81.9%, SSv2 72.2%, ImageNet 77.9% (ViT-H/16) 즉답
- Spatio-temporal masking의 구체적 디자인 이해
- 'Feature prediction only'의 의미와 비교 대상 SSL 명확
- Frozen evaluation의 의미와 attentive probe
⚠️ 레드 플래그
- V-JEPA를 I-JEPA의 단순 시간 확장으로만 이해
- Kinetics와 Something-Something의 차이 모름
- Frozen evaluation의 의미 모름
- 'Feature prediction only'의 비교 대상(VideoMAE, CLIP 등) 모름
🎤 예상 인터뷰 질문
- V-JEPA의 spatio-temporal masking을 구체적으로 설명해 주세요
- Kinetics-400과 Something-Something-v2의 벤치마크 차이는?
- 'Frozen backbone + attentive probe' 평가의 의미는?
Key Takeaways
V-JEPA 기본정보
arXiv 2404.08471, 2024-02-15, Bardes 1저자.
Spatio-temporal masking
시간+공간의 큰 tube를 가림.
K400 81.9%
일반 동작 분류 SOTA 근접.
SSv2 72.2%
미세 동작 이해의 표준 벤치.
ImageNet 77.9%
비디오 학습 → 이미지로 전이.
Feature prediction only
ImageNet pretrained X, 텍스트 X, negative X.
Frozen evaluation
Backbone 동결 + 작은 probe로 표현 품질 측정.
World Model의 첫 후보
상태 표현 + 미래 예측 + 추상 수준 갖춤.