V-JEPA 2 — Scale and Action (2025)
V-JEPA 2 — 1.2B 파라미터와 로봇 제어
2025년 6월 11일 Meta가 공개. arXiv 2506.09985. 1.2B 파라미터, 100만 시간 이상의 인터넷 비디오로 사전학습. V-JEPA 2-AC 변형은 DROID 데이터 62시간 미만으로 액션 조건화, Franka 로봇 zero-shot pick-and-place 65-80%. 단순 비디오 모델에서 'World Model'로의 본격 진입.
Overview
2025년 6월 11일. arXiv 2506.09985. V-JEPA 2 발표. 이 논문이 JEPA 시리즈의 가장 큰 도약이다 — "비디오 SSL 모델"에서 "실전 World Model"로의 진입.
이번 장은 V-JEPA 2의 정확한 사실(스케일·결과)과 그 의미를 본다. 특히 "zero-shot"의 정확한 의미를 두 번 강조 — Meta의 마케팅과 학술적 사실을 구분해야 한다.
- V-JEPA 2의 정확한 스케일(파라미터·데이터 시간)을 외운다
- Action-conditioned 변형(V-JEPA 2-AC)의 학습 방법과 'zero-shot'의 정확한 의미를 안다
- Franka 로봇 결과(65-80%)의 정확한 의미와 caveat을 안다
- 왜 이 결과가 'World Model'의 첫 데모로 의미 있는지 이해한다
- 벤치마크 결과(SSv2 77.3%, Epic-Kitchens R@5 39.7%)의 의미를 안다
Sections
7.1 스케일 — 1.2B 파라미터 + 100만 시간 비디오
V-JEPA 2의 핵심 스케일 (검증된 사실):
- 파라미터 수: 1.2 billion
- 사전학습 데이터: 100만 시간 이상의 인터넷 비디오 + 100만 장 이미지
- 데이터셋 이름: VideoMix22M
의미:
- 1.2B는 GPT-2(1.5B)와 비슷한 스케일. 비디오 모델로는 매우 큼
- 100만 시간 비디오 = 약 115년치. 한 사람 평생을 훨씬 넘는 시각 경험
- 이미지 + 비디오 혼합 학습 — 정적 이미지의 풍부한 다양성과 비디오의 시간적 정보 모두 활용
왜 스케일이 결정적인가: V-JEPA(2024)는 ViT-H/16(~600M) 정도였다. V-JEPA 2는 2배. 그리고 데이터가 10배 이상. **"World Model은 충분한 스케일이 있어야 의미 있다"**의 첫 검증.
출처: arXiv 2506.09985, Meta AI 블로그 https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/, Meta 연구 페이지 https://ai.meta.com/research/vjepa/
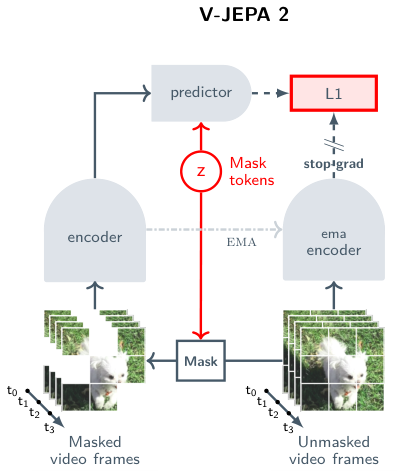
7.2 V-JEPA 2-AC — 액션 조건화로 진짜 World Model
V-JEPA 2는 두 단계로 학습된다.
단계 1 — Pretraining: 1.2B 파라미터 V-JEPA를 100만 시간+ 비디오로 self-supervised로 학습. 이 단계는 "비디오 표현 학습".
단계 2 — Action-conditioned post-training: 그 위에 "액션 조건"을 추가한다. 모델 이름이 V-JEPA 2-AC(AC = action-conditioned).
Post-training의 정확한 디테일 (verified):
- 데이터: DROID 데이터셋의 62시간 미만의 unlabeled 로봇 비디오만
- 추가 모듈: 300M 파라미터의 block-causal action transformer
- 입력 형식: 7차원 end-effector 상태(로봇 손 위치·자세) + 4초 클립 + 256×256 해상도 @ 4fps
왜 "action-conditioned"가 큰 변화인가? V-JEPA(6장)는 "비디오의 다음 부분을 예측"만 했다. 즉 "세상이 알아서 흘러간다"는 가정. V-JEPA 2-AC는 "내가 이런 행동(action)을 하면 다음에 어떻게 될까"를 학습.
이게 진정한 World Model의 정의 — 4장에서 본 LeCun 6모듈의 World Model 모듈이 정확히 "상태 + 행동 → 다음 상태".
출처: arXiv 2506.09985, Meta 블로그 (검증됨).
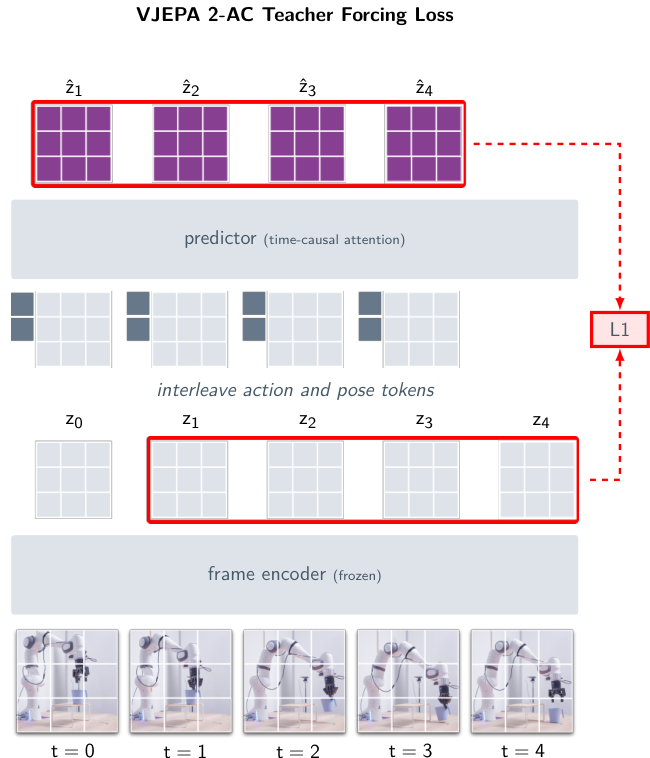
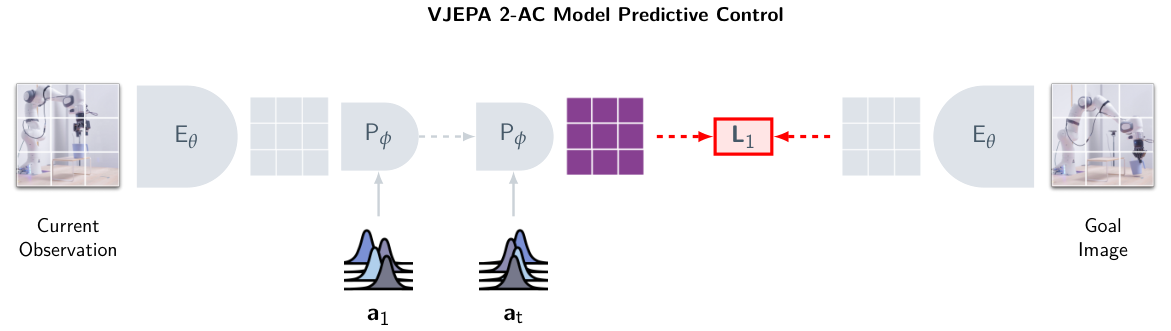
7.3 Franka 로봇 zero-shot — 65-80%의 정확한 의미
V-JEPA 2의 가장 화제 된 결과: Franka Emika Panda 로봇 팔에서 zero-shot pick-and-place 65-80%. 이 결과의 정확한 의미를 풀어쓰면.
실험 설정 (verified):
- 환경: 두 곳의 새로운 실험실의 Franka Emika Panda 로봇 팔. 둘 다 V-JEPA 2가 학습 중에 본 적 없는 환경.
- 그 환경에서 데이터 수집·태스크별 학습·보상 없음
- 입력: image goal (도달해야 할 목표 상태의 이미지)
- 태스크: pick-and-place (집어서 다른 위치에 놓기), reach (특정 위치에 손 보내기)
결과:
- Reach: ~100%
- Pick-and-place 컵(cup): ~80%
- Pick-and-place 박스(box): ~65%
"Zero-shot"의 정확한 의미 (이 caveat이 본 코스의 가장 중요한 주의): → **"새로운 환경에 환경별 데이터 없이 작동"**의 의미이며, V-JEPA 2-AC 자체는 DROID 62시간으로 post-trained된 모델이다. → 즉 "DROID로 학습한 모델이 다른 실험실의 Franka에 일반화"이지, "완전히 처음 보는 로봇"이 아니다. → 65%는 "box" 객체 평균이며 "flawless"가 아니다.
이 nuance를 정확히 전달하지 않고 "V-JEPA 2가 zero-shot으로 로봇을 한다!"라고만 하면 학술적 부정확. 마케팅 프레이밍과 학술 보고는 다르다.
출처: arXiv 2506.09985, Meta 블로그 verbatim '62 hours of robot data', '65% – 80%'.

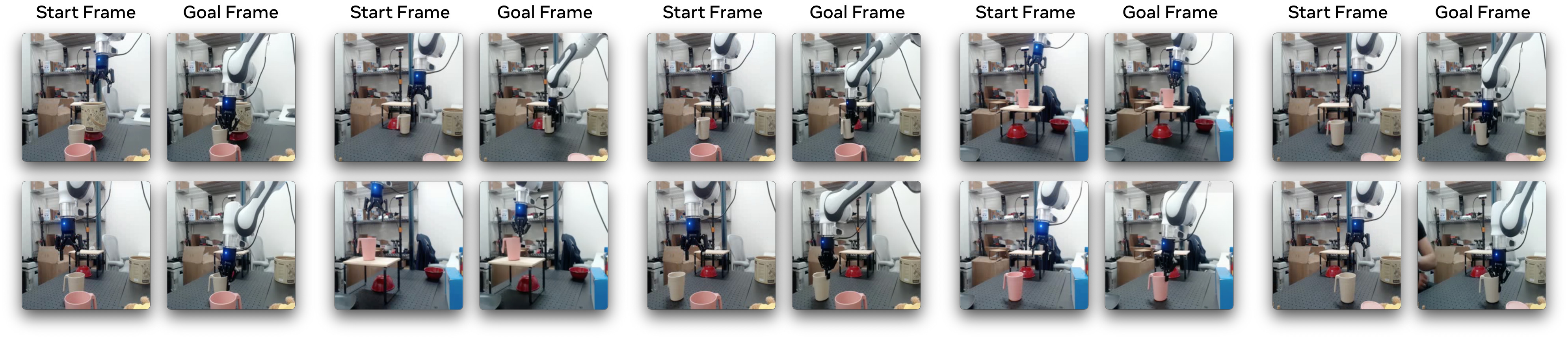
7.4 그 외 벤치마크 결과
V-JEPA 2의 다른 검증된 벤치마크 결과:
Motion understanding:
- Something-Something v2: 77.3% top-1 (이전 SOTA 갱신)
- 후속 V-JEPA 2.1: 77.7%로 추가 갱신
Human action anticipation:
- Epic-Kitchens-100: 39.7 recall-at-5 (ViT-g384, 1B 파라미터)
- "이전 태스크별 모델을 능가"
의미:
- SSv2는 V-JEPA(72.2%) → V-JEPA 2(77.3%)로 5%p 향상. SSL 모델로 비디오 분류의 새 SOTA.
- Epic-Kitchens R@5 39.7%는 "몇 초 뒤 사람이 어떤 행동을 할까"를 예측하는 anticipation 벤치. World Model의 핵심 능력.
- 두 벤치 모두 task-specific 학습 없이 frozen evaluation으로 달성 — JEPA 표현의 일반성을 보여줌.
출처: arXiv 2506.09985 초록 verbatim.
7.5 V-JEPA 2가 의미하는 것 — 그리고 한계
의미:
- World Model의 첫 실전 데모. 단순 비디오 분류가 아니라 로봇이 새 환경에서 실제 행동.
- "임베딩 공간 예측"이 실제로 작동. 픽셀 안 만들고도 행동 결정 가능.
- Scale이 의미 있음. V-JEPA(600M) → V-JEPA 2(1.2B)에서 질적 점프.
그러나 한계 — Meta 자신이 인정 (verified):
- 인간이 쉽게 풀 수 있는 "물리 추론" 벤치마크(IntPhys 2, MVPBench, CausalVQA) 에서 인간 85-95%, V-JEPA 2 포함 모델들은 chance 수준에 가까움. (자세한 건 8장)
- 65-80%는 "완벽"이 아님. 35%는 실패.
- 환경 일반화는 "실험실 Franka 두 곳"으로 제한된 평가. 산업 환경의 robustness는 미검증.
JEPA 시리즈에서의 위치: V-JEPA 2가 "World Model이 정말 가능한가"의 첫 양성 신호. 그러나 인간 수준은 멀었고, V-JEPA 3나 후속 모델이 어디까지 갈지가 본 분야의 가장 큰 관심사. 이게 9장 "논쟁"과 10장 "다른 학파"의 컨텍스트.
운전을 배우려는 사람이 두 단계를 거친다.
단계 1 — 시뮬레이터: 수많은 운전 영상을 보고 "길이 굽으면 차도 따라가야 한다", "앞 차가 가까우면 브레이크" 같은 일반적 "세상의 작동 방식"을 학습. 자기 행동을 시뮬레이터가 받아주진 않음. 그냥 보면서 배움.
단계 2 — 시뮬레이터 + 조작: 핸들·페달이 추가된 시뮬레이터로 "내가 핸들을 돌리면 차가 어떻게 움직이는가"를 학습.
단계 1이 V-JEPA의 학습이고, 단계 2가 V-JEPA 2-AC의 post-training. 그 다음 진짜 차를 처음 운전했는데 50미터 안에 사고 없이 출구를 빠져나간다면 — 그게 zero-shot 적용이다.
V-JEPA 2의 65-80%는 "진짜 차로 처음 운전, 65-80%의 경우 출구를 잘 빠져나갔다"는 의미. 인상적이지만 100%는 아니다. 그리고 그 시뮬레이터(DROID)에서 학습했기 때문에 100% "처음"은 아님 — 이 nuance가 중요. 그러나 단계 2까지 가능했다는 자체가 World Model이 실전에 가까워졌다는 신호다.
V-JEPA 2-AC의 핵심 아이디어 — 비디오 표현 학습 + action transformer post-training — 의 의사 코드. 실제 학습은 거대하지만 구조는 단순.
import torch
import torch.nn as nn
# Stage 1: V-JEPA pre-training (Chapter 6's V-JEPA, scaled up to 1.2B)
class VJEPA(nn.Module):
def __init__(self, num_params='1.2B'):
super().__init__()
self.context_encoder = ViT_H_16_video() # ~1.2B params
self.target_encoder = ViT_H_16_video() # EMA copy
self.predictor = ViT_predictor()
def pretrain(self, video_dataset):
# 100M+ hours of internet video, spatio-temporal masking
for video in video_dataset:
loss = vjepa_step(video, self.context_encoder,
self.target_encoder, self.predictor)
backprop(loss)
# Stage 2: V-JEPA 2-AC (Action-Conditioned)
class VJEPA2AC(nn.Module):
def __init__(self, pretrained_vjepa):
super().__init__()
# Frozen pre-trained encoder
self.encoder = pretrained_vjepa.context_encoder
for p in self.encoder.parameters():
p.requires_grad = False
# 300M block-causal action transformer
self.action_transformer = nn.Transformer(
d_model=1024, num_heads=16, num_layers=24
)
# 7-D end-effector state input
self.state_embed = nn.Linear(7, 1024)
def predict_next(self, current_video, current_state, action):
"""Given (video, state, action) → predict embedding of next state."""
s = self.encoder(current_video) # frozen visual encoder
state_token = self.state_embed(current_state)
action_token = self.embed_action(action)
# Block-causal: can attend to past but not future
seq = torch.cat([s, state_token, action_token], dim=1)
next_state_embed = self.action_transformer(seq)
return next_state_embed
def train_droid(self, droid_subset_62h):
# Less than 62 hours of unlabeled robot videos from DROID
for video, state_seq in droid_subset_62h:
for t in range(len(state_seq) - 1):
pred = self.predict_next(
video[t], state_seq[t], action=infer_action(state_seq[t], state_seq[t+1])
)
target = self.encoder(video[t+1]).detach()
loss = ((pred - target) ** 2).mean()
backprop(loss)
# Stage 3: Zero-shot deployment on a new Franka arm
def zero_shot_pick_and_place(model, current_obs, goal_image):
goal_embed = model.encoder(goal_image)
for step in range(MAX_STEPS):
# Sample candidate actions, pick the one that reaches the goal
candidates = sample_actions()
scored = [(a, distance(
model.predict_next(current_obs, get_state(), a), goal_embed
)) for a in candidates]
best = min(scored, key=lambda x: x[1])[0]
execute(best)
세 단계가 V-JEPA 2의 흐름. (1) 비디오 100만 시간으로 일반 시각 표현 학습. (2) DROID 62시간으로 action transformer post-training — 이 단계가 '내가 행동하면 어떻게 될까'를 모형에 추가. (3) 새 Franka에서 zero-shot — goal_image로 목표 임베딩을 만들고, 후보 action을 시뮬레이션해서 "가장 goal에 가까운" action을 실행. 이게 LeCun 6모듈에서 World Model + Cost + Actor의 조합.
✅ 시니어가 보는 것
- 1.2B 파라미터·100만+ 시간 비디오·VideoMix22M 즉답
- V-JEPA 2-AC의 학습 데이터(DROID 62h)와 action transformer(300M) 디테일
- 'Zero-shot 65-80%'의 정확한 의미와 nuance
- SSv2 77.3%, Epic-K R@5 39.7%의 의미
⚠️ 레드 플래그
- 'V-JEPA 2는 zero-shot으로 모든 로봇을 한다'의 과장
- DROID post-training을 모르고 "완전 zero-shot"이라고 말함
- 65-80%를 'flawless'로 표현
- Meta 마케팅과 학술 사실을 구분 못 함
🎤 예상 인터뷰 질문
- V-JEPA 2의 'zero-shot'이 정확히 무엇을 의미하는지 풀어 설명해 주세요
- V-JEPA 2-AC의 학습 데이터와 변형은?
- 65-80%의 결과를 객관적으로 평가하면?
Key Takeaways
V-JEPA 2 기본정보
arXiv 2506.09985, 2025-06-11. Meta FAIR.
1.2B 파라미터
GPT-2급 스케일. 비디오 모델 최대.
100만+ 시간 비디오
VideoMix22M. 사람 평생 시각의 100배.
V-JEPA 2-AC
Action-conditioned. World Model 정의 충족.
DROID 62h post-training
이게 'zero-shot'의 nuance.
Franka 65-80%
Cup ~80%, box ~65%. Reach 100%.
SSv2 77.3% (SOTA)
후속 V-JEPA 2.1: 77.7%.
마케팅 vs 학술
'Zero-shot' 표현은 환경 기준임을 명시.